
Is Your Data Team a Dashboard Factory?
Part 0 of 5: The Problem. The first dashboard I built at HCA got opened four times. Total. Not four times a day. Four times ever.

The first dashboard I built at HCA got opened four times. Total. Not four times a day. Four times ever.
I'd spent eleven days on it. Custom SQL, well-designed layout, clear KPIs. The clinical ops director had requested it specifically. She opened it twice, her deputy opened it once, and someone from finance clicked on it by accident. (I checked the access logs like a psycho.)
175 hospitals in that system. $1.2M in annual cost savings from the reporting automation program I eventually built there. But that first dashboard? Dead on arrival. Not because the data was wrong. Because nobody had asked what decision it was supposed to change.
I was a dashboard factory of one.
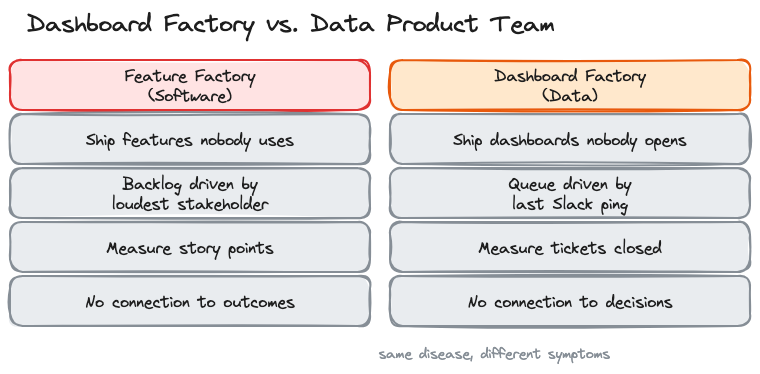
The Dashboard Factory
In 2016, John Cutler wrote "12 Signs You're Working in a Feature Factory" and product teams collectively flinched. The diagnosis was brutal: shipping features nobody asked for, measuring output instead of outcomes, no connection between what gets built and what moves the business.
Marty Cagan put it even sharper: "it doesn't matter how good your engineering team is if they are not given something worthwhile to build."
Data teams have the same disease. We just call it something different.
Instead of shipping features nobody uses, we ship dashboards nobody opens. Instead of a Jira backlog driven by the loudest stakeholder, we have a queue of ad hoc requests driven by whoever pinged us last on Slack. The metrics change (tickets closed per sprint instead of story points) but the dysfunction is identical.
Nick Zervoudis calls it a "service-oriented data team." Joe Horgan calls it the "dashboard factory operating model." I've lived in both versions. The pattern is the same: you build what people ask for instead of what they need. You measure how fast you build it instead of whether it changed anything. And quarter by quarter, the gap between your output and your impact gets wider.
The Diagnostic
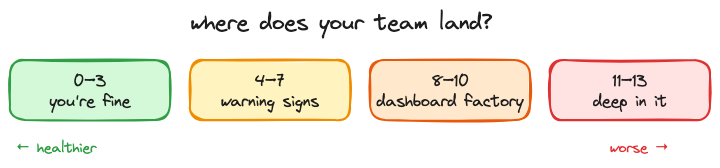
Zervoudis published 13 signs of a service-oriented data team. I've adapted them here with my own commentary. Score yourself honestly. If you hit 8 or more, you're deep in it.
1. Stakeholders ask for specific visualizations instead of help with business questions. They say "I need a bar chart of monthly revenue by region." they should be saying "we're losing market share in the southeast and I don't know why." the first request gets you a dashboard. The second gets you a data product.
2. You've built a large number of reports and dashboards, and suspect most aren't being used. At NeuroBlu, I audited our analytics platform and found that nearly half of dashboards hadn't been opened in 90 days. Nobody noticed they were gone when we archived them. Nobody.
3. You find out about upstream schema changes after something breaks. I got paged at 2am once because a vendor changed a field name in their API. No migration notice. No changelog. Our pipeline broke, and three downstream dashboards showed zeroes for six hours before anyone noticed. When your team is the last to know about changes that directly affect your work, you're not part of the system. You're downstream of it.
4. You spend hours every week playing "number detective." The CFO's number doesn't match the VP's number, which doesn't match yours. Same metric, three different definitions, and your morning is now a forensic accounting exercise instead of building the thing that would prevent this from happening again. At NeuroBlu, I spent more time reconciling conflicting metrics across teams than building the analytics that would have standardized them.
5. Stakeholders have forgotten they requested something by the time you deliver it. Three-week turnaround on a "critical" request. You deliver it, send the link, get back "oh, we already handled this a different way." the urgency was real when they asked. By the time you delivered, the decision had already been made without data. That's the tax of a reactive queue.
6. Your workload is ad hoc requests, not strategic projects. Look at your last two weeks. Count the hours spent on requests that came in via Slack DM versus hours spent on work your team planned. If the ratio is worse than 60/40 in favor of ad hoc, you're not running a team. You're running a help desk with SQL skills.
7. You don't know what stakeholders do with the data you give them. This one haunts me. I'll dig into this more in Part 1, but the short version: a join bug inflated our cohort numbers by 40% at NeuroBlu and a client's analyst found it in a board meeting before we did. They'd built their quarterly forecast on our numbers. I had no idea how the data was being used downstream because nobody's workflow included that feedback loop.
8. Your team doesn't own its own roadmap. If your roadmap is just a list of things other people asked for, it's not a roadmap. It's a delivery queue.
9. Your success is measured by outputs, not outcomes. Tickets closed. Dashboards shipped. Reports delivered. None of which tell you whether anyone made a better decision because of your work.
10. You call people outside the data team "the business." The language tells you where the divide is. If there's "the data team" and "the business," you've already lost. You're a service bureau, not a product org.
11. Your quarterly priorities are decided by someone else. Someone in leadership sets your team's goals. You execute them. You don't get to say "actually, the highest-impact thing we could do this quarter is X." your roadmap is a delivery queue with a fancier name.
12. You get requests after decisions are made. "we decided to launch this. Can you build the reporting?" that's the gut-punch version of every sign on this list. The decision happened without data. Your team gets called in for the cleanup. You're not informing strategy. You're documenting it after the fact.
13. You can't quantify the monetary value your team adds. If the CFO asked you right now what your team is worth in dollar terms, could you answer? Most data teams can't. And that's why they get treated as cost centers.
Why This Happens
Five root causes. All of them are organizational, not technical.
You're positioned as a service function. The data team reports into IT or engineering instead of product. That reporting line defines your purpose: you exist to serve requests, not to drive outcomes. Your budget gets justified by how many tickets you close, not by what decisions you changed.
Nobody applied product thinking to data. Cagan's four risks (value, usability, feasibility, business viability) apply to data products the same way they apply to software products. Most data teams skip the first two. They validate feasibility ("can we build this pipeline?") and viability ("does the infrastructure support it?") but never ask "will anyone actually change their behavior because of this?"
Your methodology was designed for software, not data. Scrum, Kanban, SAFe. All designed for teams that ship code. Data teams have different rhythms. A data scientist needs three to five weeks of exploration before she can even scope the problem. You force that into a two-week sprint and she either rushes the exploration or carries it across sprints until everyone loses track. The methodology doesn't fit, so the team works around it, and the workarounds become the process.
Handoffs are informal. Context travels through Slack threads, meeting notes, and tribal knowledge. When work moves from the PM to the data scientist to the engineer, critical assumptions evaporate at each boundary. The PM knows why this cohort was chosen. The data scientist knows what edge cases were excluded. The engineer knows neither. I've watched entire quarters of work collapse because of one implicit assumption that nobody documented. (I'll dig into the worst version of this in Part 1.)
Nobody owns the fifth risk. Cagan's framework includes four risks. Data products need a fifth: data ethics and quality. Who's accountable when a model performs differently across demographic groups? Who catches the bias before it ships? In most teams, that job belongs to everyone, which means it belongs to no one.
Here's what makes all of this hard to fix. Joe Horgan nails it: "operating as a dashboard factory is often hard-wired into data teams. Ad hoc changes won't stick in an operating model that's designed to frustrate them." you can't fix it by hiring better analysts or buying better tools. Chad Sanderson argues that data's core problem is trust and communication, not technology. He's right, but you also can't fix it by just telling people to communicate better. You need the structure that makes good communication the default.
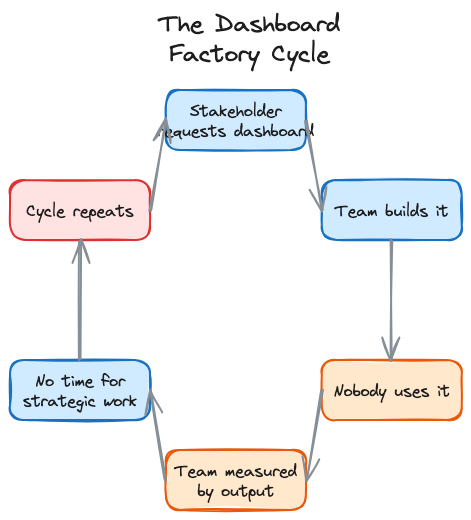
The Escape Route
I've been building a system around this since late 2023.
It started with the handoff problem. Every failure I described above traces back to the same root: context disappearing when work crosses from one person to another. What if handoffs were contracts instead of conversations? What if every time work moved between roles, there was an explicit agreement about what context transfers, what assumptions are in play, and what needs to be true before the next person builds on it?
I call it DPOS, the Data Product Operating System. It's an operating model: the principles, practices, and contracts that define how a data team discovers, builds, ships, and evaluates data products. Each role keeps its own workflow. The contracts connect them. This is a five-part series covering the kernel principles, role-specific operating systems, the integration layer that connects them, and practical implementation paths for teams at different maturity levels.
So What
The hard part isn't building better dashboards. It's recognizing that the dashboards were never the product. The decisions they were supposed to enable? Those are the product.

Dashboard factories don't need better dashboards. They need to stop being factories.
Next in series: Part 1: Introduction — The Operating System for Data Products
Series Navigation:
- Part 0: The Problem — You are here
- Part 1: Introduction
- Coming soon: Part 2 — The Kernel (Principles)
- Coming soon: Part 3 — Role Operating Systems
- Coming soon: Part 4 — The Integration Layer
- Coming soon: Part 5 — Implementation