Product Management
The DPOS Kernel: Principles for the AI Era
Part 2 of 5: The 15 principles that form the foundation of the Data Product Operating System. Seven philosophical beliefs about how data products work differently, and eight strategic principles for making decisions.
What Is the Kernel?
Klarna's AI customer service handled 2.3 million conversations per month. It cut resolution time from 11 minutes to 2. By every metric the team was tracking, it was a success.
Then Klarna hired 250 human agents back.
The AI worked too well. As Nate Jones puts it: "The distinction between AI that fails and AI that succeeds at the wrong thing is the most important unsolved problem in enterprise AI right now." Klarna had optimized for "resolve tickets fast" when the actual goal was "build lasting customer relationships." The system was executing flawlessly against the wrong intent.
Stuart Winter-Tear frames the underlying problem: "Autonomy is cheap. Bounded autonomy is the work." Every data team has access to capable AI, fast pipelines, and decent tooling. The scarce thing isn't capability. It's the control plane that turns capability into purposeful action, the set of principles that define what "right" looks like before the first line of code gets written.
That control plane is the kernel.
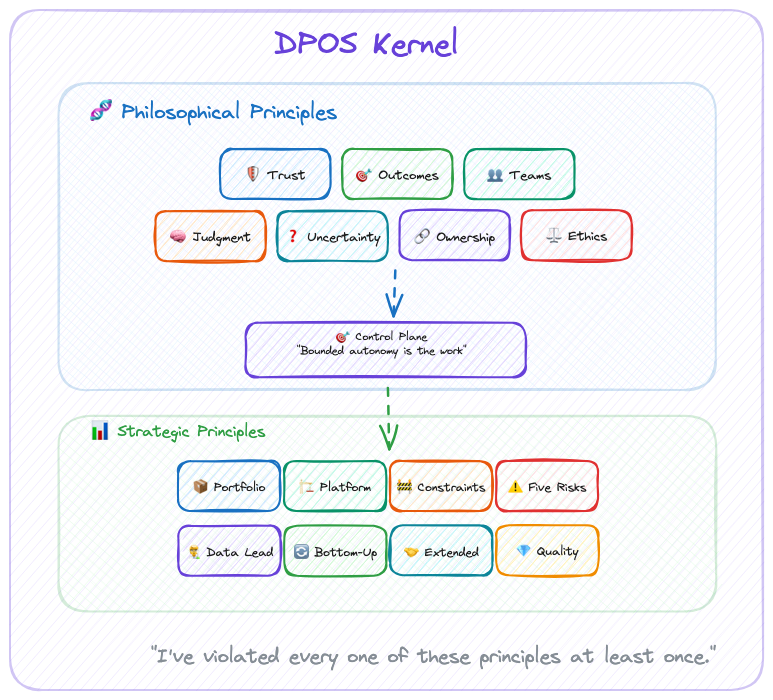
For DPOS, the kernel consists of two layers:
- Philosophical Principles: How we see the world of data products
- Strategic Principles: How we make decisions based on that worldview
These principles inform every decision, from team formation to technology choices to portfolio strategy. They work whether you're a solo builder or leading a 100-person data organization.
The modules adapt. The kernel never does.
The Seven Philosophical Principles
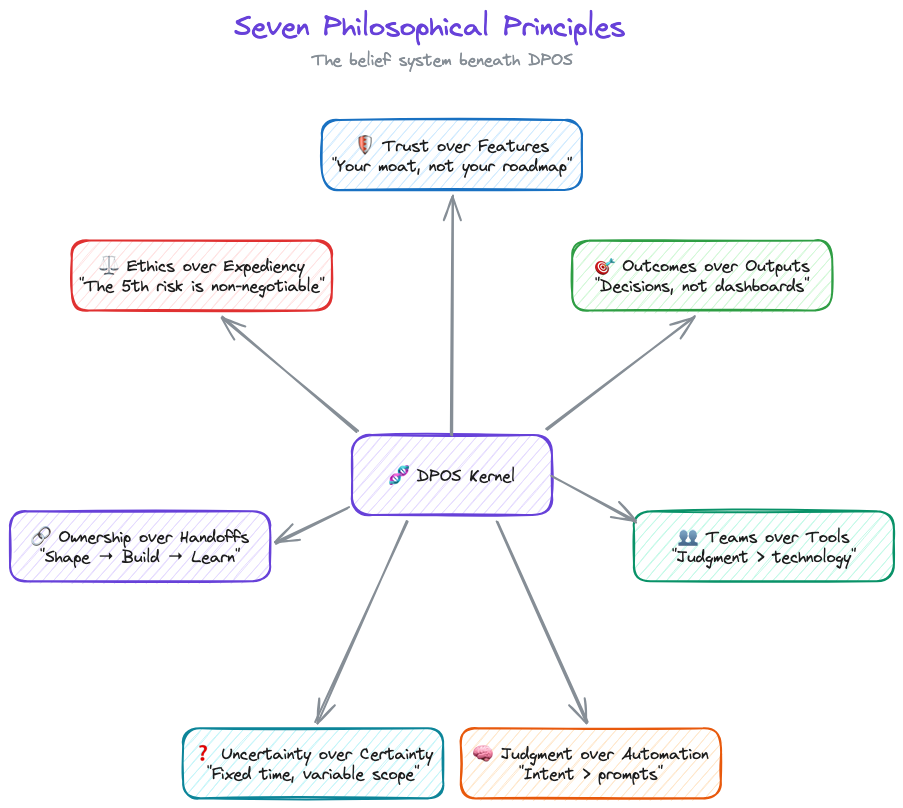
DPOS is built on seven core beliefs about how data products work differently. You'll disagree with at least one. That's fine. The point isn't agreement. It's having a position.
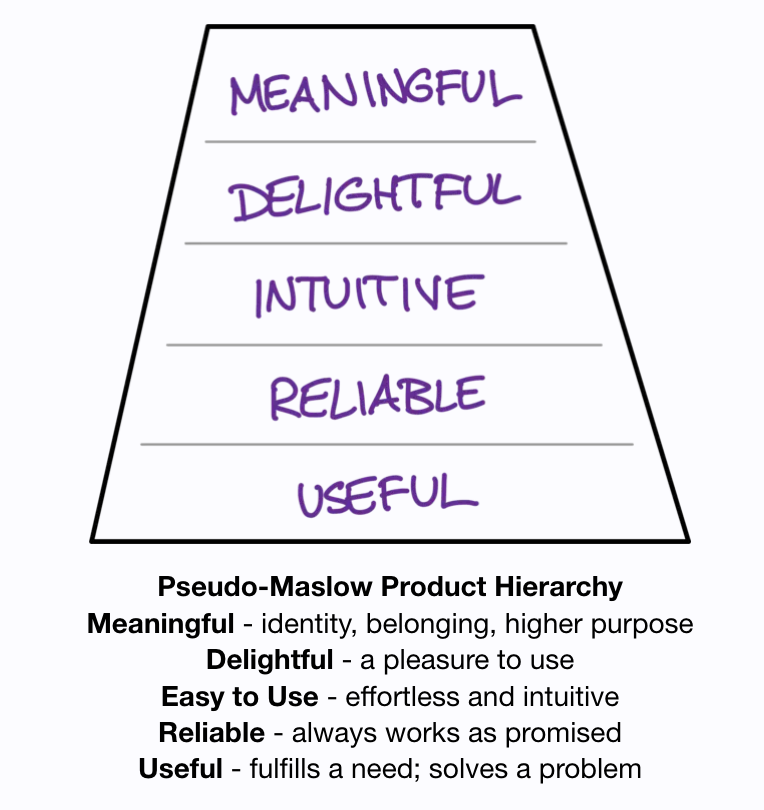
1. Trust over Features
Data products live or die on trust. A single data quality incident can destroy months of relationship-building. Every decision—from architecture choices to release timing—must prioritize trust preservation.
This isn't feel-good philosophy. It's economic reality. NeuroBlu's $6M ARR came from clients who trusted our data, not clients impressed by our ML algorithms. When one data quality incident cost us a $300K renewal, the lesson was permanent: features attract customers, but trust keeps them.
Last year I delayed a feature launch by two weeks to fix a lineage gap nobody outside the team would have noticed. My leadership was not thrilled. The client renewed. I'll take that trade every time.
2. Outcomes over Outputs
Data teams love showcasing capabilities: "Look at our 99.9% accuracy!" But customers buy outcomes: "I can make clinical decisions 3x faster."
One VP told me: "We have 47 dashboards and no answers." That's the difference between outputs and outcomes. The dashboards existed. The decisions didn't get easier. Somewhere along the way, the team optimized for "things we shipped" instead of "problems we solved."
The shift from "what our data can do" to "what our customers can achieve" separates successful data products from expensive science projects. Products deliver value; projects deliver outputs.
The fix is simple and uncomfortable: define what success looks like before you define what to build. Measure decisions made, not dashboards shipped. If your roadmap reads like a feature list instead of a value proposition, you're building a project, not a product.
3. Teams over Tools
After building $7M in data product ARR, I can tell you the technology was never the hard part. (I spent six figures on a BI platform that solved the wrong problem before I learned this.) DuckDB vs Snowflake doesn't matter if your team can't make good decisions. Getting the right people in the right roles, with clear ownership and strategic thinking, that's the 80% that determines success.
Tools are commoditized. Judgment isn't.
Before you debate DuckDB vs. Snowflake, ask: does your PM know what customers actually need? Does your data lead have authority to say "not yet" on a release? Get the people right first. The tools will follow.
4. Judgment over Automation
Nate Jones describes three layers of AI capability: prompt engineering (what to do), context engineering (what to know), and intent engineering (what to want). Almost nobody is building the third layer. That's where the failures live.
Klarna proved this. Great prompts, great context, zero intent alignment. Nobody encoded "build lasting relationships" in a way the system could act on.
I've trained 100+ executives on GenAI adoption. Every session proves the same point: teams that obsess over the technology fail. Teams that focus on the judgment framework, who decides, when to override, what requires human review, succeed. As Winter-Tear puts it: "Tools can encode clarity. They cannot create it." The judgment principle isn't about humans being better than AI. It's about clarity being a prerequisite that no tool provides automatically.
AI handles synthesis, pattern recognition, mechanical analysis. Humans handle strategy, ethics, and anything where context matters more than speed. And if AI starts eroding trust? You pull back. Speed you can recover. Trust you can't.
5. Uncertainty over Certainty
Data work requires exploration. You can't know if the data quality supports your hypothesis until you've tested it. You can't predict algorithmic bias until you've examined the training data.
Fixed time, variable scope respects this reality. Two-week sprints pretend data work is predictable. (It isn't. If your data scientist can scope a problem in two weeks, it wasn't a hard problem.) Six-week cycles acknowledge the uncertainty.
Shape for 2 weeks before committing to 6-week cycles. Make go/no-go decisions based on what you've actually discovered, not what the Gantt chart predicted. Success means "did we solve the problem?" not "did we finish the backlog?"
6. Ownership over Handoffs
The strategy-execution chasm kills data products. When the "strategy team" hands off to the "execution team," context gets lost and ownership fragments.
The people shaping the product are the people building the product are the people learning from customer feedback. No strategy consultants. No separate "architecture team." No handoffs. If that sounds impossible in your org, that's the diagnosis, not the objection.
7. Ethics over Expediency
The 5th risk—ethical data risk—is non-negotiable. When deadlines loom, teams cut corners on bias testing, privacy reviews, and transparency mechanisms. That's how algorithmic discrimination happens. That's how trust collapses.
Data Lead ownership of ethics isn't bureaucracy. It's insurance against existential risk.
Data Leads have authority to delay releases for ethical concerns. Bias testing, privacy review, and transparency mechanisms are never negotiable scope. Governance that enables speed, not bureaucracy that prevents it. But when ethics conflicts with deadlines, ethics wins. Every time.
Seven principles. Sounds clean. Maybe too clean. I've watched plenty of frameworks that look perfect in a blog post and collapse on contact with a real team. The honest version: I've violated every one of these principles at least once. Trust over Features is easy to say when you're not staring at a renewal deadline with a feature gap. Judgment over Automation is easy to say when the CEO isn't asking why you're not shipping faster with AI.
These principles survive not because they're comfortable. They survive because the cost of ignoring them was always higher than the cost of following them. Usually I learned that after the fact.
The Eight Strategic Principles
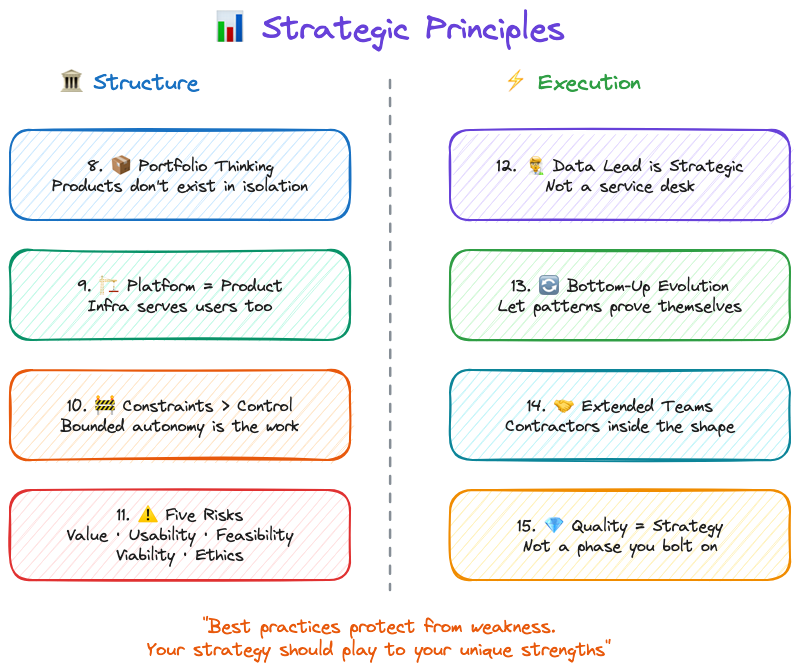
Philosophical principles are the beliefs. Strategic principles are what those beliefs look like when you're actually running a team.
One note before we get into these: the point of strategy is to be different. To find alpha. Copying best practices protects you from known weaknesses, but it doesn't play to your strengths. These strategic principles are a starting position, not a ceiling. If your team has a way of working that creates advantage nobody else can replicate, protect that. Don't sand it down because a framework told you to.
The Data Product Strategy Stack
Pichler's strategy stack goes from business strategy at the top to product backlog at the bottom. For data products, I add two layers he doesn't: portfolio strategy (because when data is both infrastructure AND product, individual strategies fragment without it) and platform strategy between portfolio and product (because your architecture IS your competitive moat, not just an implementation detail).
Everything else flows the same way. Except one thing: the flow is bidirectional. Discoveries from building, quality issues from shipping, feedback from customers, all of it flows back up to change strategy. Strategy that doesn't adapt to reality is just a slide deck.
8. Data Products Need Portfolio Thinking
When data is both infrastructure (shared platform) AND product (revenue-generating offerings), individual product strategies can create fragmentation, duplication, or competitive conflicts.
Portfolio strategy sets boundaries that enable product strategies to innovate.
I've watched this pattern across healthcare data companies at every scale. IQVIA, Truveta, Change Healthcare, Veradigm, all of them run multiple data products that share infrastructure but serve different markets. The ones that win have portfolio-level governance. The ones that don't end up with three teams building slightly different versions of the same cohort builder. At NeuroBlu, we had a healthcare data platform and provider network SaaS with unified trust frameworks but distinct product strategies. The portfolio layer is what kept them from cannibalizing each other.
Portfolio strategy sets data governance standards, trust frameworks, platform patterns, and cross-product sharing protocols. Product strategies determine target markets, value propositions, feature sets, and pricing models. Head of Data Products owns portfolio plus platform strategy. Product Squads own individual product strategies.
9. Platform Strategy Is Product Strategy
Traditional products can separate "product decisions" (features, UX) from "platform decisions" (infrastructure, architecture). Data products can't. Your data architecture IS your competitive moat. Platform decisions are business decisions.
CensusChat choosing DuckDB enabled sub-second queries on 44GB datasets, which enabled the product value proposition (instant insights from massive datasets). NeuroBlu choosing a columnar architecture enabled 30x data scale (0.5M → 32M patients), which enabled enterprise contract wins. Snowflake's architecture—separation of storage/compute, data sharing—IS their product differentiation, not just infrastructure.
Platform decisions get evaluated for business impact, not just technical merit. (If your CTO and your Head of Product haven't co-authored a roadmap, you have two roadmaps. That's worse than having none.) Technology roadmap and product roadmap are co-created, or they're fiction.
10. Alignment Through Constraints, Not Control
Top-down control kills innovation. Bottom-up chaos kills alignment. Portfolio strategy must balance both.
Dylan Anderson puts it plainly: "To succeed with Data Governance, organisations need one thing above all else: Structure. Without it, you will frustrate individuals and undermine the role governance should play." Structure doesn't mean bureaucracy. It means boundaries that enable speed.
Winter-Tear identifies what happens without those boundaries. Organizations survive on what he calls "tolerated vagueness," fuzzy ownership, undocumented escalation paths, informal workarounds that humans patch in real time. That works until you add AI or scale the team. Then, as he writes, "delegated systems don't simply accelerate the workflow. They accelerate the consequences of whatever ambiguity was already there."
Set boundaries, not mandates. Product strategies innovate within constraints.
For data products, constraints might look like: "All products must maintain 99.9% data accuracy" (trust framework), but how you achieve it is your choice. "Algorithmic bias testing required before production" (ethical data risk), but which testing methodologies you use is up to you. "Data lineage must be observable" (quality standard), but which lineage tools you choose is your call.
Portfolio strategy defines "what" must be true. Product strategies define "how" to make it true. Constraints enable autonomy by clarifying boundaries. Betting tables resolve resource conflicts across products.
11. Strategy Owns the Five Risks
Traditional product strategy addresses four risks (Marty Cagan): value, usability, feasibility, business viability. Data products add a fifth.
Product strategy must address the fifth risk with the same rigor as the other four.
Cagan's four are familiar: Value (will customers use it?), Usability (can they figure it out?), Feasibility (can we build it?), and Business Viability (does it work for our business?). Most teams address these, even if imperfectly.
The fifth risk is the one that gets skipped: Ethical Data Risk. Can we build trust while delivering value? This means bias testing, privacy review, transparency mechanisms, governance design. Owned by the Data Lead, not by committee.
Ethical data risk cannot be "addressed later" or "fixed in production." When risks conflict, speed vs. ethics for example, the Data Lead has authority to delay. Address it or don't ship.
12. Data Lead Ownership Is Strategic
Adding a Data Lead to the team seems like an operational decision. (It's not. It's the most strategic hire most data teams never make.)
Data Lead ownership of the 5th risk is strategic recognition that data products have different DNA.
Trust destruction is existential. A single data quality incident can destroy an entire product's market position. Ethical risk requires expertise—algorithmic bias, privacy, transparency aren't things product managers can "pick up." And there's no fallback position. If the Data Lead doesn't own ethical data risk, nobody does. It won't be owned by committee.
Roman Pichler talks about empowered teams having authority to create and evolve product strategy over time, offering three key benefits: fast decision-making and strategy-execution alignment, increased productivity, and value focus.
For data products, empowerment requires four pillars, not three: Product Manager (market & strategy), Tech Lead (architecture & implementation), Design Lead (UX & visualization), and Data Lead (data science, engineering, ethics).
Data Lead is present from strategy formation through delivery. Data Lead has veto authority on ethical concerns. Data Lead is accountable for trust metrics. If you don't have someone in this seat, ask yourself who's accountable for the next data quality incident. If the answer is "everyone," the real answer is no one.
13. Bottom-Up Strategy Evolution
Strategy that ignores reality fails. Top-down strategy that never adapts to discoveries is dogma.
Quality issues from building reveal portfolio gaps. Customer feedback reveals strategy pivots. Platform problems reveal architecture changes. The flow in the strategy stack goes both ways. Strategy is a living document, not sacred text.
14. Extended Teams for Extended Reach
Your core squad (PM, Tech Lead, Design Lead, Data Lead) doesn't have every expertise you need, so bring in legal, clinical, commercial, and compliance as collaborators early in shaping, not as gatekeepers late in approval.
At NeuroBlu, Legal identified HIPAA considerations upfront, not during QA. Medical Affairs validated the clinical value proposition before launch, not after. The difference between "we invited compliance to review" and "compliance helped us shape it" is about six weeks of rework.
15. Quality Is Strategy, Not Tactics
Dylan Anderson reframes quality in a way that changed how I think about it: "Data quality is an output, not an input. It is a symptom of numerous underlying root cause issues within the data ecosystem." Most teams treat quality as something to test for. Anderson argues that's backwards. "Tackling just 'data quality' will lead to potential short-term gain but continued long-term pain."
The numbers back this up. Gartner estimates poor data quality costs organizations an average of $12.9M per year. MIT Sloan puts it at 15-25% of revenue. That's not a QA problem. That's a strategic failure.
The root causes are systemic: broken business processes generating bad data at the source, multiple conflicting data sources with no reconciliation, no established basis for quality improvement, and chronic underinvestment in governance. You can test for quality all day. If the processes creating the data are broken, testing just documents the damage.
Quality as strategy means addressing root causes, not symptoms. Quality metrics are defined during strategy formation, not QA phase. Trust metrics sit alongside performance metrics in product dashboards. Data lineage is designed into architecture from day one. Continuous monitoring replaces checkpoint testing. Quality incidents trigger strategy reviews, not just bug fixes.
At NeuroBlu, "zero major data quality incidents" was a strategic goal, not a QA goal. Led to architecture decisions, redundant validation, observable pipelines, that differentiated us. CensusChat defined quality as "results match official Census reports exactly," which shaped architecture choice (DuckDB with validation layer) over faster options with potential discrepancies.
How the Principles Collide
Principles sound clean in isolation. In practice, they collide.
At NeuroBlu, a client wanted faster cohort generation. The fastest path skipped lineage validation. Trust over Features said no. The Data Lead flagged potential bias in the underlying patient selection. Ethics over Expediency said slow down. Meanwhile, the client was asking why this was taking so long. Outcomes over Outputs said: the outcome isn't speed, it's accuracy.
We took the slower path. Added the validation. Tested for bias. Shipped two weeks late. The client didn't mention the delay once. They mentioned three times that the numbers matched their internal validation. That's how these principles work: not as a checklist, but as a decision framework when the pressure is on and the easy path is wrong.
From Kernel to Execution: Role Operating Systems
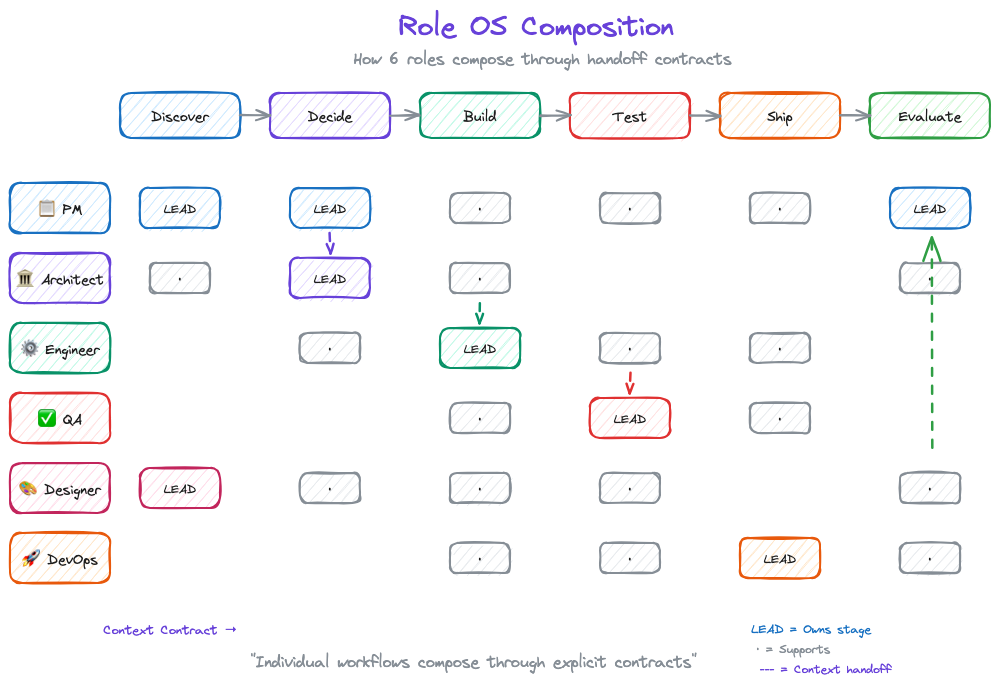
Principles are useless without execution. But here's what traditional frameworks get wrong: they jump from principles to team process. That's too big a gap.
Between "Trust over Features" (principle) and "Hold weekly quality reviews" (process) sits something critical: how individuals actually work.
DPOS v2 introduces Role Operating Systems, the layer between kernel principles and team execution.
What Is a Role OS?
Each role on a data product team operates with their own system: agents that assist them, context they consume and produce, workflows they follow. This is their Role OS.
Winter-Tear offers a sharp test for whether you've actually built one: "If you can name the workflow owner, the source of truth, the service level, and the audit trail, you are building an agent specialist. If you cannot, you are probably building a copilot, so set expectations accordingly." Role OSes are how you answer those four questions for every role on your team.
The kernel principles translate directly to Role OS design:
| Kernel Principle | Role OS Implementation |
|---|---|
| Teams over Tools | Shared context — Your OS feeds the team, not just you. The context you produce becomes input for other roles. |
| Judgment over Automation | Agents with oversight — AI assists at scale, humans decide at boundaries. Your agents handle mechanical work; you handle judgment calls. |
| Trust over Features | Deterministic where necessary — Handoffs need predictable outputs. Your Role OS guarantees quality at interfaces. |
| Ownership over Handoffs | Clear organization — Your OS owns specific lifecycle stages. You know what you're responsible for at each phase. |
The Six Role Operating Systems
DPOS v2 defines six roles, each with their own OS:
- Data PM OS — Strategy, prioritization, stakeholder synthesis
- Data Engineer OS — Pipelines, transformations, data quality
- Data Architect OS — System design, integration patterns
- QA/Data Quality OS — Testing, validation, quality gates
- Designer/BA/Visualization OS — UX, requirements, dashboards
- DevOps/App Engineer OS — Deployment, infrastructure, monitoring
Your team might have different names. You might combine roles. That's fine—what matters is that each role has a defined OS that composes into team execution.
How Role OSes Compose
Individual productivity isn't the point. Composition is.
Traditional methodologies assume everyone follows the same process. That's inflexible. Role OSes assume everyone follows their own process, connected through explicit handoff contracts.
PM OS (Discover) → Context Contract → Architect OS (Decide)
Architect OS (Decide) → Context Contract → Engineer OS (Build)
Engineer OS (Build) → Context Contract → QA OS (Test)
The team OS doesn't prescribe how each role works. It defines:
- The lifecycle stages (Discover → Decide → Build → Test → Ship → Evaluate)
- Which roles engage at each stage
- What context contracts connect them
This is what LLMs changed. Before, "my notes" stayed in my head (or my Notion). Now, structured context from your Role OS actually feeds team execution. Individual workflows compose—for real, not just in theory.
Part 3 goes deep on Role Operating Systems—what they contain, how to build them, and a complete example for the Data PM role.
If You Read Nothing Else
For executives: Your data team isn't failing—your methodology is. Stop measuring story points. Start measuring customer outcomes. The $300K we lost on one data quality incident taught me: trust is your moat, not features.
For data team leaders: The reason nobody sees your work is that Scrum ceremonies don't surface data value. These principles give you a language to explain what you do—and why it takes time to do it right.
For practitioners: It's not your fault that sprint planning feels like theater. Data work doesn't fit two-week chunks. These principles explain why, and Part 3 shows a different path.
Next up: Part 3 goes deep on Role Operating Systems. How each team member builds their own OS, and how those OSes compose into team execution through explicit handoff contracts.
Series Navigation:
- Part 1: Introduction
- Part 2: The Kernel (Principles) ← You are here
- Part 3: Role Operating Systems
- Part 4: The Integration Layer
- Part 5: Implementation
Beyond the Product Trio - Why Data Products Need a Squad
Data products need more than a trio.
Growth is driven by compounding, which always takes time. Destruction is driven by single points of failure, which can happen in seconds, and loss of confidence, which can happen in an instant. - Morgan Housel, Psychology of Money
The Team Behind Market Profiler
In my second year at Revive, I was tasked with turning a one-off healthcare market analysis project into a scalable product offering. We'd delivered a bespoke market analysis to a regional health system that had generated significant strategic impact, and leadership wanted to create a repeatable data product that could be sold to multiple clients.
Armed with a PowerPoint, Tableau workbook, and an analyst who'd crafted some impressive Alteryx/Python data pipelines, we gathered to map a way forward
The kickoff meeting included our typical product development cast: me as Product Manager, a Tech Lead responsible for implementation, and a Design Lead to craft the user experience. This tried-and-true "Product Trio" had successfully launched numerous healthcare marketing campaigns and products before.
But something wasn't clicking.
"How confident are we in the predictive model's accuracy across different market types?" asked the Tech Lead.
"What about demographic blind spots? Rural markets have different data coverage than urban ones," noted the Designer.
"And the ethical implications of giving health systems competitor intelligence? What are the elements missing between the claims, EHR, and other data sources we are considering? Are we sure about this?" I wondered aloud.
While I had the coverage and experience previously, I needed support and deep data expertise. Not just coding skills or database knowledge, but someone who who had seen healthcare data's nuances, limitations, and ethical boundaries.
The next week, I added a Data Lead to our core team - a data engineer. We moved faster and with more certainty from then on.
This was top of mind when building the next product and the team supporting it. We needed more than the standard trio of leads - we needed a squad.
The Traditional Product Trio
For years, the product development world has operated with a well-established core team structure known as the Product Trio:
- Product Manager: The voice of the market, business, and strategic direction
- Tech Lead: The technical feasibility and implementation expert
- Design Lead: The user experience and interface architect
As Teresa Torres describes it, "A product trio is typically comprised of a product manager, a designer, and a software engineer. These are the three roles that—at a minimum—are required to create good digital products."
This triad works beautifully for traditional software products. The PM understands what to build, the Tech Lead knows how to build it, and the Design Lead ensures it's intuitive and enjoyable to use.
For a typical SaaS product, this structure covers the essential disciplines needed to take a product from concept to market. Technical feasibility questions focus on software engineering challenges: Can we build this feature? How long will it take? Will it scale?
But data products are different beasts entirely.
Enter the Data Product Squad
Data products—whether dashboards, predictive models, recommendation engines, or AI-powered tools—have unique complexities that the traditional trio isn't equipped to fully address.
Enter the Data Product Squad:
- S: Strategic
- Q: Quality-focused
- U: User-centered
- A: Analytical
- D: Data-driven
At its core, the Squad consists of four essential leaders:
- Product Manager: Still the market and business expert, but with awareness of data's unique challenges
- Tech Lead: Focused on system architecture, API design, and overall implementation
- Design Lead: Creating interfaces that make complex data intuitive and actionable
- Data Lead: The data science, engineering, and ethical governance expert
The Data Lead isn't an optional add-on or a nice-to-have consultant. They're an essential fourth pillar in data product development—equal in importance to the other three roles.
The Five Risks of Data Products
Why is this fourth role so critical? Because data products face a risk profile fundamentally different from traditional software.
In his classic work on product risk, Marty Cagan of Silicon Valley Product Group discusses the "Four Big Risks" that all product teams must address:
- Value risk: Will customers buy it or users choose to use it?
- Usability risk: Can users figure out how to use it?
- Feasibility risk: Can our engineers build what we need with the time, skills, and technology we have?
- Business viability risk: Does this solution work for the various aspects of our business?
For traditional products, the Product Trio maps cleanly to these risks:
- The Product Manager addresses value and business viability risks
- The Designer handles usability risk
- The Tech Lead tackles feasibility risk
But data products introduce a fifth critical risk:
5. Ethical Data Risk
This encompasses:
- Accountability for algorithmic decisions
- Representativeness of data
- Fairness across populations
- Transparency and explainability
- Data privacy and governance
- Long-term impact and unintended consequences
This fifth risk doesn't map neatly to the traditional trio. While product managers might understand the business implications, designers might consider the user experience impact, and engineers might recognize some technical limitations, none are typically equipped to fully own this critical risk dimension.
That's where the Data Lead becomes essential.

Technical Feasibility Risk (Reimagined)
Even the nature of feasibility risk is different for data products:
In traditional software development, technical feasibility usually centers on engineering challenges: Can we build this feature? How much will it cost? How long will it take?
For data products, feasibility questions are more complex:
- Do we have enough high-quality data to train this model?
- Can we get acceptable accuracy across all key demographics?
- Is real-time prediction possible given our infrastructure?
- How do we handle data drift over time?
These questions require deep expertise in data science, data engineering, and the specific domain's data landscape. A traditional Tech Lead, while brilliant in software engineering, often lacks this specialized knowledge.
Ethical Risk (Expanded)
The ethical dimension permeates data products, especially those using AI/ML:
- Are we accidentally encoding bias in our algorithms?
- Are our recommendations creating harmful incentives?
- Do our visualizations inadvertently mislead users?
- Are we properly protecting sensitive data while still deriving value?
- Can we explain how our model makes decisions?
- Do we have proper measures to monitor, detect, and mitigate failures?
These aren't just hypothetical concerns—they're existential risks for data products. One ethical misstep can destroy trust permanently.
As the quote at the beginning reminds us: growth compounds slowly, but destruction can happen in an instant. For data products, that destruction often stems from ethical oversights that a traditional product team might miss.

Market Profiler: The Squad in Action
Returning to our Market Profiler example, adding a Data Lead transformed our approach in several crucial ways:
First, our Data Lead immediately identified critical limitations in our demographic data sources. Rural zip codes had significantly less reliable commercial data than urban ones, creating a blind spot that could lead healthcare clients to underinvest in underserved communities. We hadn't fully recognized this issue in our one-off project, but scaling it as a product would have magnified the problem.
Second, he challenged our machine learning approach for predicting service-line growth opportunities. Our initial model used classic propensity scoring, but she demonstrated how this could inadvertently prioritize wealthy, well-insured patients over those with greater needs. We pivoted to a more balanced methodology that considered both commercial opportunity and community health impact.
Finally, he designed a data governance framework that allowed us to provide competitive intelligence without crossing ethical boundaries around protected health information. This included specialized aggregation techniques that prevented reverse-engineering of sensitive metrics.
The result? Market Profiler evolved from an interesting analytics project into a responsible, ethical data product that hospitals could confidently use for strategic planning. Within a year, we had signed contracts with a half dozen health systems—far exceeding our original projections.
The NeuroBlu Experience
At Holmusk, I witnessed a similar pattern with our flagship product, NeuroBlu Analytics. When I joined, the team was structured around the traditional Product Trio model, with data scientists consulted as needed but not integrated into core decision-making.
Early versions of the product faced challenges:
- Data models were technically sound but difficult for non-technical healthcare researchers to use
- Visualizations were beautiful but sometimes misrepresented statistical significance
- The platform excelled at showing correlations but offered little guidance on causation risks
As we evolved toward a Squad approach, with a dedicated Data Lead as a core team member, these issues began to resolve. The Data Lead became our ethical compass, constantly asking questions like:
- Are we providing enough context for these findings?
- Could this visualization lead researchers to draw inappropriate conclusions?
- Are we properly communicating the limitations of real-world evidence?
This shift accelerated our platform's adoption among life science companies—groups that need a ton of support to over come general skepticism of our commercial real-world evidence approach. They recognized and respected the ethical rigor our Data Lead brought to the product.
Building Your Own Data Product Squad
If you're developing a data product, how do you implement the Squad approach?
1. Elevate data expertise to leadership level
The Data Lead isn't just a technical contributor—they need authority equal to the other leaders. They should be present for strategic decisions from day one, not consulted afterward.
2. Look for T-shaped data expertise
The ideal Data Lead has depth in one area (e.g., data science, data engineering, data visualization or data governance) but breadth across the entire data lifecycle. They should understand enough about each area to identify risks and ask the right questions.
3. Value domain knowledge
Domain expertise is particularly critical for the Data Lead. In healthcare, for instance, understanding HIPAA, clinical workflows, and healthcare economics is as important as technical skills.
4. Create clear decision rights
Define which team member has final say in which areas. The Data Lead should have veto power on issues of data quality, model performance, and ethical use.
5. Establish data ethics principles
Work as a Squad to define ethical boundaries before you're faced with difficult tradeoffs. Document these principles and review them regularly.
The Future of Data Product Teams
Marty Cagan recently published a thought-provoking vision for how AI might reshape product teams, predicting that "product discovery will become the main activity of product teams, and gen ai-based tools will automate most of the delivery."
But even in this AI-accelerated future, Cagan still sees the need for specialized roles: "product teams will need a product manager to solve for the many business constraints, a product designer to solve for the user experience, and an engineer to solve for the technology."
For data products, I'd argue the same logic applies to the Data Lead. As AI becomes more integrated into products of all types, the need for data expertise at the leadership level will only grow, not diminish.

The line between "regular products" and "data products" will continue to blur. Eventually, all digital products may need something like the Squad approach.
But for now, if you're explicitly building a data product—particularly one that uses machine learning, predictive analytics, or works with sensitive information—the traditional Product Trio isn't enough.
You need a Data Product Squad, with the Data Lead as an essential fourth pillar.
Because data products don't just carry technical and market risks—they carry ethical risks too. But at the end of the day - not much is different. You still need to figure out what and how to build and distribute something that users value.

The Questions Nobody's Asking
- How do we measure the impact of ethical data product decisions on long-term customer trust?
- What skills and training do Product Managers need to work effectively with Data Leads?
- How does the Squad approach scale across multiple product teams in larger organizations?
- In an AI-augmented future, will the Data Lead become even more critical as ethical risks multiply?
- How do we balance innovation speed with ethical risk management in data product teams?
Would love to hear your thoughts. Have you seen the need for a dedicated Data Lead on your data product teams? What challenges have you faced when developing data products with traditional team structures?
{kind=link}
Building products and companies is about managing continuous uncertainty.
You never know enough about the customer, market, competitors, and world at a point in time. Technology and possibilities are constantly changing. The competitors are doing their best to cut you off at the knees and redefine a market. Your customer has personal preferences and is influenced by shifting tastes. It's impossible to understand it all at once.
"Managed chaos" is real in startups and products. The extremes of "plan and research every detail" and "YOLO" aren't the answer - it's somewhere in between.

So what does that look like?
Especially in complex product or startup markets (B2B, data, international B2C) - what do you do?
The 5D Product Framework: An Overview
The Design Council in 2004 released the Double Diamond into the design world. If you have been in design, startups, or marketing - you would be familiar with the Double Diamond.

It's a process of moving from exploring (divergent thinking) to defining (convergent thinking). It's a continuous process - never fully static - moving from discovery to decision then back as needed.
While the framework generally applies to any design scenario (which products and companies are inherently designed), it always struggled when I shared it broadly. The general applicability, a blessing in many ways, can be a curse. The Double Diamond often was met with "ok but how does this apply to me and what next?"
So introducing:
5D Product Framework
Define > Discover > Design > Develop > Decide
This framework is an attempt to put context, flow, and expectations to the inherently fluid process of "deciding what to build".
But the core is simple - talk to users, identify what to build, build, and repeat.
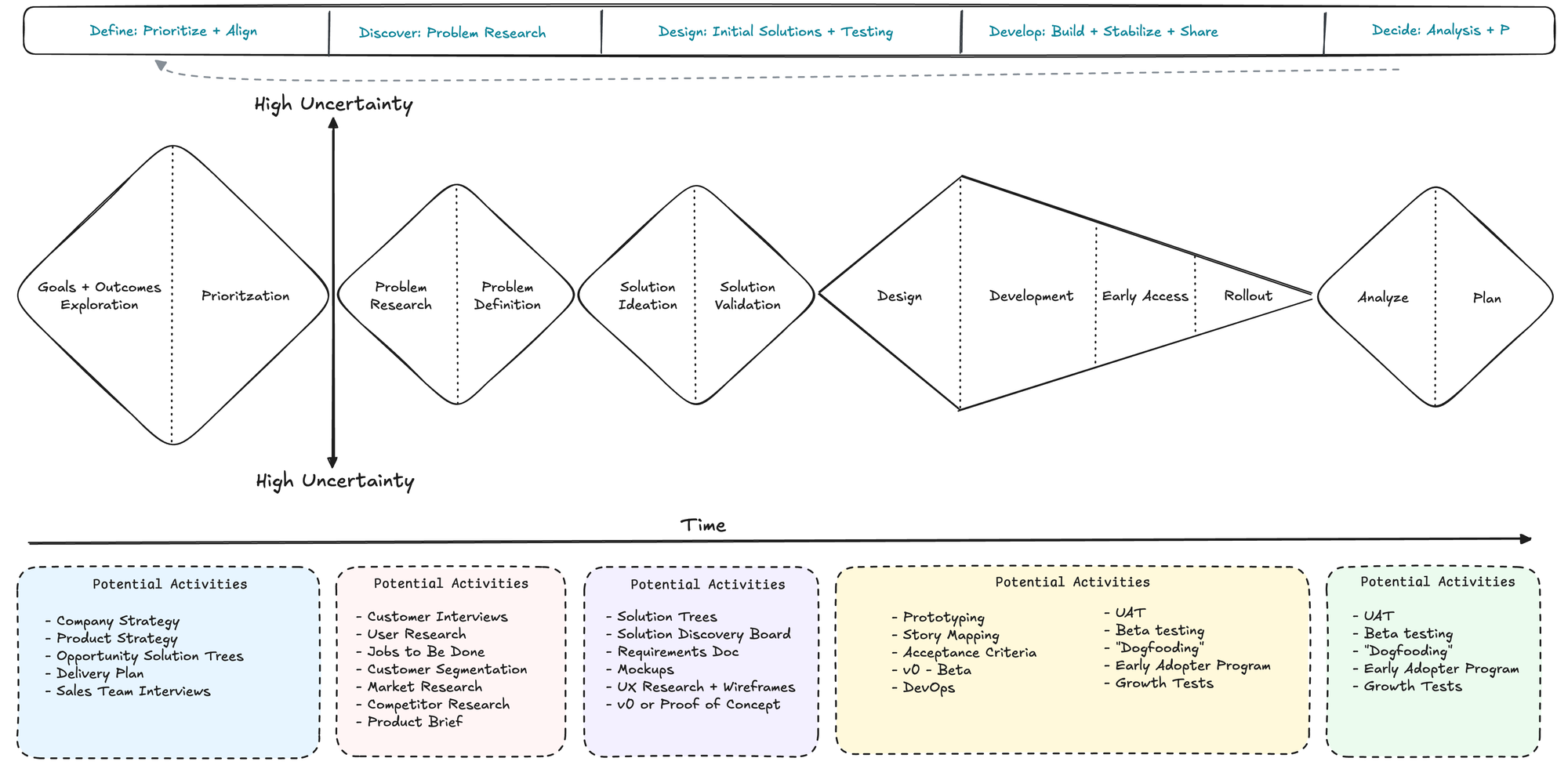
1. Define: Prioritize and Align
The first D is about getting your house in order. Just like in healthcare, you need a diagnosis before treatment. Define is your diagnosis phase.
Key Activities:
- Company + Product Strategy: Setting clear direction and scope
- Quarterly OKRs: Measurable goals that align with strategy
- Opportunity Solution Trees: Mapping problems to potential solutions
Tips for Effective Prioritization:
- Start with the "why" - what problem are you really solving? Why is this important to solve now for your users?
- A prioritization framework (such as RICE) is helpful to combat HiPPO (Highest Paid Person Opinion) issues but don't be a beholden to it. Prioritization requires looking at the full picture and making decisions - even if they seem irrational to someone on the outside
- Focus on one big bet per quarter - don't try to boil the ocean. You will do at best half of what you plan. It's ok.
Remember: There are only two criteria for product success:
- Does it solve a user's problem well?
- Does it help business move forward?
That's kind of it. Sorry 🤷🏻♂️

2. Discover: Problem Research and Solution Validation
- Activities: Customer Segmentation, Customer Interviews, JTBD Mapping
- Balancing problem discovery with solution validation
- Case study or example of successful problem research
This is where the rubber meets the road. Just like in data, garbage in = garbage out.
Key Activities:
- Customer Segmentation: Who exactly are we building for?
- Customer Interviews: What are their actual problems?
- Jobs To Be Done (JTBD) Mapping: What are they trying to accomplish?
The Discover phase is about balancing depth with speed. You're not writing a PhD thesis - you're trying to understand enough to take informed action. Get a sense of the use case and understand it deeply.
Case Study: Marketing Analytics Dashboard
When I was building analytics dashboards at a healthcare marketing agency, everyone wanted to "go big" - build flashy brand launches, complex visualizations, get perfect attribution, integrate external context.
But when we actually talked to users, they just wanted to answer simple questions:
- How are my campaigns performing?
- Where should I allocate budget?
- What's working and what's not?
Users don't "want the data" - they want insights and something to help them make progress in their decisions.

3. Design: Crafting the Product Experience
Design isn't just about making things pretty - it's about making them work. In healthcare tech, this is especially crucial. There is serious "low hanging fruit" in building intuitive data product interfaces and "giving people a dashboard" is not the answer.
Key Activities:
- UX Research: Understanding user workflows and pain points
- Design Sprints: Rapid ideation and validation
- High-fidelity Prototyping: Testing with real users
- Note: don't stop with 2-3 users, getting a diverse set of opinions from your customer personas needs to include 5-10 points of direct feedback. Don't lie to yourself.
The Iterative Process:
- Start simple
- Get feedback
- Refine
- Repeat
Pro tip: KISS (Keep It Simple, Stupid). Accept complexity when necessary, data products especially are by nature complex and you can't avoid this, but lean towards simplicity, design, and empathy. Run from "complicated".

4. Develop: Building and Preparing for Launch
Development is where ideas become reality. But remember - the goal isn't to build everything perfectly. It's to build enough to learn. Shoot for something that is Simple, Loveable, Complete.
Key Activities:
- Story Mapping: Breaking down features into manageable chunks
- QA/DevOps: Ensuring quality and reliability
- UAT: Testing with real users
- Feature Go-to-Market Planning: Preparing for successful launch
Common Pitfalls:
- Over-engineering solutions
- Perfectionism paralysis
- Feature creep
- Forgetting about the end user
5. Decide: Analyzing and Improving
The final phase transforms instincts into evidence, where your data infrastructure proves its real value and insights drive action. Success here means implementing systematic feedback loops that actually inform product decisions, not just collecting data for data's sake.
Customer Interviews: Getting qualitative feedback
- Run structured exit interviews with churned customers while scheduling monthly power user deep-dives to understand what works and what doesn't
- Track feature requests and patterns in a searchable repository, capturing verbatim quotes that illuminate real user needs - Interview Snapshots are gold for sharing this with leadership and others
- Build and maintain systematic feedback loops that connect directly to product planning > back to the beginning. Connect feedback into the Define phase.
Product Metrics: Measuring what matters
- Focus on actionable metrics that drive decisions: time to first value, core action completion rates, feature adoption velocity, and engagement depth scores
- Skip the vanity metrics (if you can) and build real-time dashboards with clear next actions, implementing anomaly detection that catches issues before they become problems
- Connect every metric to a specific product or business outcome that matters
Cohort Analysis: Understanding behavior over time
- Map usage patterns to revenue outcomes and monitor product stickiness to understand what keeps users coming back
- Build cohort analyses that reveal which user characteristics and behaviors predict success

Implementing the 5D Product Framework
Use it. Don't use it. Copy. Adapt it.
The goal is to "decide what to build", build it, and see if the market responds. Rinse and repeat.
Managing Uncertainty and Learning
- Strategies for reducing uncertainty throughout the product lifecycle
- How to maximize learning at each stage of development
- The role of experimentation and iteration in the 5D framework
Conclusion
Building products is hard. Building good products is harder. Building great products requires a framework that balances structure with flexibility.
The 5D Framework isn't perfect - no framework is. But it provides a path through the chaos, a way to manage the endless uncertainty of product development. It's helped me - hope it helps you.
Remember:
- Define, Discover, Design, Develop, Decide > repeat
- Data, LLMs, algorithms, systems aren't magic - they are tools
- Quality matters, especially in healthcare and other regulated industries
- Treat your users, data, and team well, and incredible things can happen
What's your take? How do you manage product development uncertainty? Let me know in the comments.
Additional Resources
Define
- Getting better at product strategy - Lennys Newsletter
- Product Strategy - Reforge
- Mission, Strategy, and Tactics - Boz
- Mission - Vision - Strategy - Goals - Roadmap - Tasks - Lennys Newsletter
Discover
Design
- PM - Design Partnership - Lennys Newsletter
- Building beautiful products - Katie Dill
- What is product design - Figma
Develop
- The engineering mindset - Will Larson
- Making better estimates with engineers - Jason Evanish
- Learning Track: Working with Developers - Technically Substack
Decide
{kind=link}
Growth is driven by compounding, which always takes time. Destruction is driven by single points of failure, which can happen in seconds, and loss of confidence, which can happen in an instant. - Morgan Housel, Psychology of Money
Working with data requires holding two things true at once. You must constantly investigate, experiment, and explore while building certainty, understanding, and stability. It’s about trust. Bringing some order to chaos which is what data is.
General product management - a vague notion I know but think of any physical product or technical service - relies on the former truth with the latter coming as the investigation comes to a close.
When building with data, there is always something new with your input. The ground is shifting under your feet. It makes sense to flow with it.
Over the years of building data products and teams, I’ve found a couple of differences. Not massive but real. And worth talking about.
Core Focus & Responsibilities
- User-Centric DNA: Everything revolves around user needs and experiences
- Broad Scope: Lives at the intersection of engineering, business, and UX
- Qualitative Decision-Making: Heavy reliance on user feedback and market insights
Data Product Management:
- Data-Centric DNA: Data shapes every decision and feature
- Specialized Scope: Operates where engineering, business, and data meet
- Quantitative Decision-Making: Lives and dies by metrics and experiments
This is a dramatic simplification. A data product manager is a product manager first. Jason Cohen writes, “the role centers on deciding what to build.” It’s deceptively simple and a data product manager has to do the same. The difference lies in the material and constraints.
A SaaS PM is product focused and while they have to manage the business viability risk (can the business support and benefit from this product), they often have fewer hard constraints on what to build with.

The Skills Gap That Actually Matters
General PMs need:
- Market research chops
- Customer development expertise
- Business strategy understanding
- Basic technical knowledge
In addition to those core things, Data PMs require:
- Reasonable data science understanding
- Machine learning/AI experience
- Data governance appreciation
- Analytics proficiency
This is asking a lot of one person. True. Add in some element of data expertise and you have a future founder on your hands.
The demands are impossible. The job is technically impossible. That's why you are on a team. It's not on you but you need to bring context, creativity, and an ability to coach.
Team Dynamics & Collaboration
General PM Teams often include:
- Cross-functional squads (engineers, designers, marketers) helmed by the Product Trio (PM, Tech Lead, Design Lead)
- Customer feedback drives development
- Focus on feature shipping and user adoption
Data PM Teams:
- A similarly cross-functional squad but helmed by a Product Quad (Data PM, Tech Lead, Design Lead, and Data Lead) with data-centric specialists (data scientists, data engineers, analysts) added in
- Data quality drives development
- Focus on data accessibility and democratization
Data products are inherently more complex. Especially if they are B2B which 90% of them are. Balancing the quality risk along with the other four (value, usability, feasibility, and business viability per Marty Cagan) is just icing on the cake.

The Healthcare Reality Check
In healthcare, these differences become even more pronounced. When I was leading data product at Revive, we weren't just shipping features - we were shipping trust. We had to build the story for our healthcare partners while still maintaining strict controls on protecting patient data.
Healthcare B2B is "playing on hard mode". Building a data product in a regulated industry like US healthcare requires a focus on quality risk above all else.
Four Key Shifts That Nobody Talks About:
- The Risk Profile
- General PM: Ship (potentially) buggy code, push a fix
- Data PM: Ship bad data, lose trust forever
- The Success Metrics
- General PM: Usage, engagement, retention
- Data PM: Data quality, decision velocity, trust signals
- The Customer Journey
- General PM: "Wow, this is great!"
- Data PM: "I don't trust this yet... but maybe..."
- The Team Dynamic
- General PM: "When can we ship?"
- Data PM: "How do we validate?"
Looking Ahead
As AI and ML become ubiquitous, these roles will continue to merge. But the fundamental differences in approach - particularly around risk, trust, and validation - will remain critical. As noted in the lead quote, growth is compounding, in markets and products, but trust can be lost in an instant.
Every product will have data components. But not every product will be a data product. Understanding this distinction will be an important skill for the next generation of PMs.
The Questions Nobody's Asking
- How do we measure trust as a product metric?
- What does "move fast and break things" look like when data quality is non-negotiable?
- How do we build data products that balance innovation with reliability + trust?
Would love to hear your thoughts. What differences have you noticed between Data PM and General PM roles in your work?
{kind=link}
10 Uncommonly Useful Observations on Product-Market Fit for Data Products
Forget what you know about product-market fit for traditional SaaS—data products play by a different rulebook. In this post, I share ten uncommonly useful observations from my years in the healthcare data trenches, challenging conventional wisdom and providing a roadmap for success in the complex wo
As a veteran in the healthcare data product space, I've seen my fair share of successes and failures when it comes to achieving product-market fit. While many principles from traditional SaaS products apply, data products have their own unique challenges and opportunities. Here are ten uncommonly useful observations that can help you navigate the complex landscape of product-market fit for data products.
1. The "Aha!" moment is often delayed
Standard SaaS expectation: Users should have an immediate "Aha!" moment upon first use.
Data product reality: The true value of a data product often emerges over time as patterns and insights accumulate. Your onboarding process needs to set the right expectations and provide early wins while building towards the bigger picture.

2. Your product is only as good as your data sources
Standard SaaS expectation: Product quality is primarily determined by features and user experience.
Data product reality: The quality, freshness, and relevance of your data sources can make or break your product. Invest heavily in data acquisition, cleansing, and integration. Remember, garbage in, garbage out.

3. Customization is not just a feature, it's a necessity
Standard SaaS expectation: One-size-fits-all solutions with minor customization options.
Data product reality: Every organization's data landscape is unique. Your product needs to be flexible enough to accommodate diverse data structures, integration points, and use cases without becoming overly complex.
4. The sales cycle involves education and change management
Standard SaaS expectation: Demonstrate value quickly and close the deal.
Data product reality: Selling a data product often requires educating prospects on data literacy, changing existing processes, and aligning multiple stakeholders. Your sales process should include elements of consultative selling and change management.
5. Success metrics are often indirect
Standard SaaS expectation: Direct metrics like user engagement and feature adoption indicate success.
Data product reality: The true impact of your data product might be several steps removed from direct usage. Success could manifest as better decision-making, cost savings, or revenue growth for your clients. Develop ways to track and attribute these indirect benefits.

6. The "network effect" is data-driven
Standard SaaS expectation: More users lead to more value through increased interactions.
Data product reality: More data often leads to better insights and predictions. Consider how you can create virtuous cycles where using your product generates more valuable data, which in turn makes the product more valuable for all users.
7. Regulatory compliance is a feature, not a bug
Standard SaaS expectation: Compliance is a necessary evil.
Data product reality: In regulated industries like healthcare, robust compliance features can be a major selling point. Embrace compliance as a core feature and competitive advantage, not just a checkbox.

8. The product evolves with the data science field
Standard SaaS expectation: Periodic feature updates based on user feedback and market trends.
Data product reality: Advances in data science and machine learning can fundamentally change what's possible with your product. Stay on the cutting edge and be prepared to make significant pivots as new techniques emerge.
9. User personas include both humans and algorithms
Standard SaaS expectation: Focus primarily on human end-users.
Data product reality: Your product might need to serve both human analysts and automated systems or AI models. Design your APIs and data outputs with both in mind.

10. The MVP is more complex but potentially more powerful
Standard SaaS expectation: Build a simple MVP to test core assumptions quickly.
Data product reality: Your MVP needs to include not just basic features, but also data pipelines, quality checks, and initial models or analyses. While this makes the MVP more complex, it also means you're testing a more complete value proposition from the start.
Conclusion
Achieving product-market fit for data products requires a nuanced understanding of the unique challenges and opportunities in this space. By keeping these observations in mind, you can avoid common pitfalls and focus on the elements that truly drive value for your users.
Remember, in the world of data products, your goal isn't just to fit the market — it's to evolve with it, shape it, and ultimately, to help your users make better decisions through the power of data.
20 Leadership + Product Lessons from a Healthdata Guy
Here are 20 lessons covering building data products, working with teams, and being a better version of who you already are.
Brian Balfour, founder of Reforge, went through an excellent list of ten lessons with Lenny Rachitsky this week. I thought this was such a great interview, and his lessons were inspiring (I even borrowed a couple), so I made a list of my own.
Navigating healthcare data products has sharpened my approach to leadership. Halfway through my career, I've stacked up lessons. Some through triumphs, others through missteps.
Data is our lived experience. Knowledge is the interpretation of it. Wisdom is the application.
Here are 20 lessons covering building data products, working with teams, and being a better version of who you already are.
1) There are really only two criteria for products success:
- Does it solve a user's problem well?
- Does it help the business move forward?
That’s kind of it. Sorry 🤷🏻♂️
2) Garbage in, garbage out.
Data isn’t magic. Neither are LLMs, ML, algorithms, systems, or anything else.
Quality matters, especially in healthcare. Treat your data and your people well, and incredible things can happen.
3) Do the opposite.
When building an analytics team at a healthcare marketing agency, we would constantly be asked to go big - build a flashy brand launch.
Then, six months later - doctors on billboards.
You don’t stand out by copying others. When you say you are “better,” all everyone hears is “the same.” Be different.
But when you zag, others will follow.
So then zig. And repeat.
4) Follow the incentives.
Healthcare in the US is a mess. Everyone knows it.
Why isn’t it changing? Follow the incentives or, more simply, “the money.”
Your idea might help millions, but as Sister Irene Kraus coined, “No Margin, No Mission.”
The Iron Triangle of Healthcare still holds. Access, Quality, or Cost - pick two.
5) Bring solutions, not just problems.
Leaders context switch.
A lot.
This is doubly true at startups. Act as a magnifying glass and focus a leader on relevant info in an area; don't be a "fisheye lens" and scatter the focus. Be positive, avoid politics as much as possible, and show consistent initiative.
6) Plan to replan.
As I learned in my time as an officer: battle plans never survive first contact with the enemy.
Replace the enemy with “the market,” which still holds. The way you react sets the tone for the entire team and organization.
It requires you to be contradictory elements at once: measured but decisive, calm but quick-thinking, and systematic but flexible.
It takes practice, but know that the team needs you when you contact “the market.”
7) Fish or teach how to fish. Know the time for both.
There is a time for executing and a time for strategy. A time for focus and a time for discovery.
The divergence and convergence of the Double Diamond depends on where you are.
It’s okay to build and okay to plan. Learn when to do either.
8) Praise in public, punish in private.
Share compliments and praise (they must be genuine) generously and immediately. Spread liberally, but remember - only praise if it's genuine.
Provide feedback on time, in person (or as close to it as possible), and most importantly, in a one-on-one with psychological safety.
9) KISS: Keep it simple, stupid.
Lean towards simplicity, design, and empathy. Accept complexity when necessary.
Whether it’s data, ML, healthcare, consulting, people, teams, or any other options, try the simple option first. Accept complexity when necessary.
10) Never underestimate the power of small, focused teams.
Building 0-1 products, agile thinking, and working with incredible men and women in the military all point to a fundamental truth - small, empowered groups with a vision do amazing things.
From the Law of Small Teams to the reality of Conways Law, small teams with autonomy, complementary skills, and a vision can get it done. Fact.
11) Users rent or hire your product.
Understand the bigger picture and don't take them for granted.
12) When you try to be everything to everyone, you accomplish being nothing to anyone.
True for products, companies, philosophies, and people.
Be opinionated. Stand for something. Stand against something else.
13) Problems never end (and that’s okay).
When you solve one problem, congratulations! You’ve graduated to another, likely more difficult, one.
Expect this, relish the challenge, and be excited about a problem - not your solution.
14) Do not be a slave to tools. Tools change, your expertise improves.
I fell for it early. Tableau, that is.
A tool that inspired me; it was intoxicating and introduced me to flow state.
More importantly than the tool, I discovered data analytics. I discovered data modeling. I discovered products. I discovered design.
Tools are hammers. Problems are nails.
Don’t focus on hammers - what matters are the nails.
15) Moats weather and dissolve. Build bridges, so you don't become an island.
Strategy eggheads love to talk about “moats.” Ways to protect and play defensive.
It may work in the short term but rarely in the long term.
Moats protect you, but markets move on, and users look elsewhere if you aren’t careful.
Build bridges - especially in healthcare. We need more of those.
16) Trust, but verify.
Give the benefit of the doubt and lead with positive intent.
But keep a sharp eye out.
17) God first, patients second, team/family/friends/customers third, yourself fourth, company last.
Keep perspective.
18) Be dependable and build relationships. Healthcare and, specifically, data is small, and you will see these people again.
Life is small. Healthcare is really small; healthcare data is really, really small. True in any other market especially in B2B or in circles you should care about.
Be kind, remember that perspective, and help others out. You never know when you might need them.
19) Think in systems, speak in structures, act in experiments.
Systems thinking is your superpower if you want to build in healthcare or work in data. John Cutler is one of the best at this.
Don’t speak in systems. Speak in stories, anecdotes, summaries, and with purpose. This is what moves people and conveys purpose.
“Strong opinions, loosely held” is a great mantra for operating. You know what you know, but remember - plan to replan.
20) Accept the things you cannot change, find the courage to change the things you can, and develop the wisdom to know the difference.
Serenity Prayer - Reinhold Niebuhr
Christianity and Stoicism - two philosophies that have shaped me and many before me. It's good to have a compass.
{kind=link}