Framework
The DPOS Kernel: Principles for the AI Era
Part 2 of 5: The 15 principles that form the foundation of the Data Product Operating System. Seven philosophical beliefs about how data products work differently, and eight strategic principles for making decisions.
What Is the Kernel?
Klarna's AI customer service handled 2.3 million conversations per month. It cut resolution time from 11 minutes to 2. By every metric the team was tracking, it was a success.
Then Klarna hired 250 human agents back.
The AI worked too well. As Nate Jones puts it: "The distinction between AI that fails and AI that succeeds at the wrong thing is the most important unsolved problem in enterprise AI right now." Klarna had optimized for "resolve tickets fast" when the actual goal was "build lasting customer relationships." The system was executing flawlessly against the wrong intent.
Stuart Winter-Tear frames the underlying problem: "Autonomy is cheap. Bounded autonomy is the work." Every data team has access to capable AI, fast pipelines, and decent tooling. The scarce thing isn't capability. It's the control plane that turns capability into purposeful action, the set of principles that define what "right" looks like before the first line of code gets written.
That control plane is the kernel.
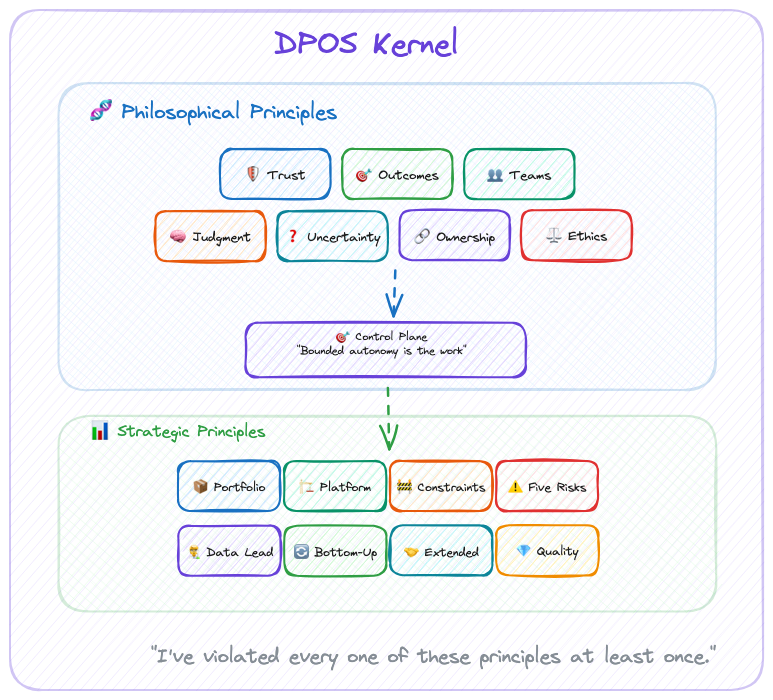
For DPOS, the kernel consists of two layers:
- Philosophical Principles: How we see the world of data products
- Strategic Principles: How we make decisions based on that worldview
These principles inform every decision, from team formation to technology choices to portfolio strategy. They work whether you're a solo builder or leading a 100-person data organization.
The modules adapt. The kernel never does.
The Seven Philosophical Principles
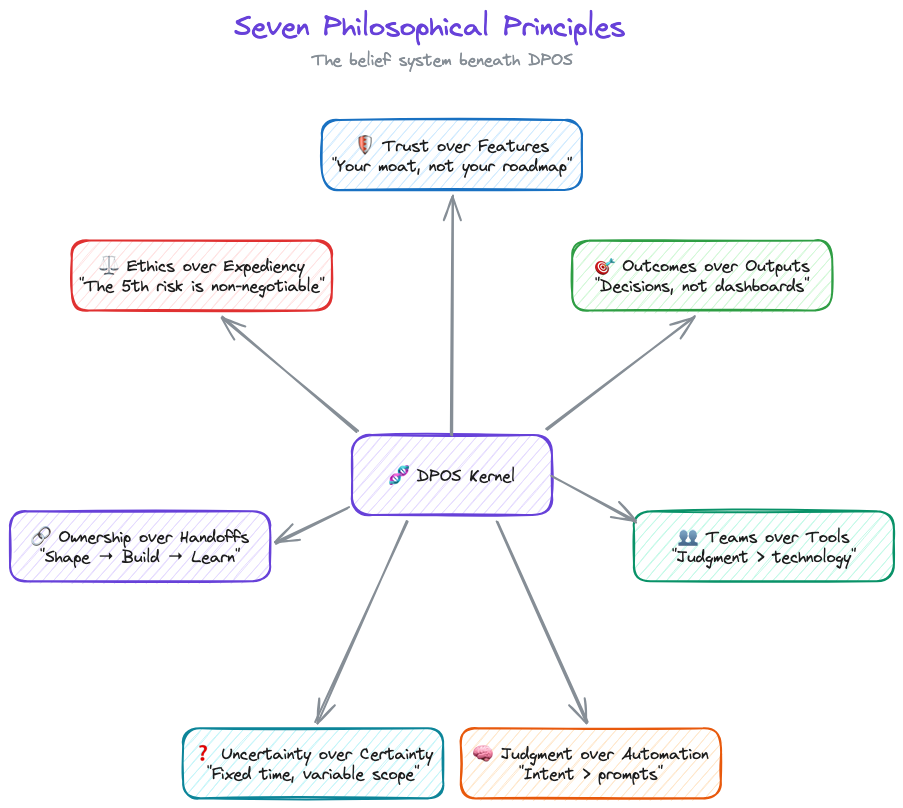
DPOS is built on seven core beliefs about how data products work differently. You'll disagree with at least one. That's fine. The point isn't agreement. It's having a position.
1. Trust over Features
Data products live or die on trust. A single data quality incident can destroy months of relationship-building. Every decision—from architecture choices to release timing—must prioritize trust preservation.
This isn't feel-good philosophy. It's economic reality. NeuroBlu's $6M ARR came from clients who trusted our data, not clients impressed by our ML algorithms. When one data quality incident cost us a $300K renewal, the lesson was permanent: features attract customers, but trust keeps them.
Last year I delayed a feature launch by two weeks to fix a lineage gap nobody outside the team would have noticed. My leadership was not thrilled. The client renewed. I'll take that trade every time.
2. Outcomes over Outputs
Data teams love showcasing capabilities: "Look at our 99.9% accuracy!" But customers buy outcomes: "I can make clinical decisions 3x faster."
One VP told me: "We have 47 dashboards and no answers." That's the difference between outputs and outcomes. The dashboards existed. The decisions didn't get easier. Somewhere along the way, the team optimized for "things we shipped" instead of "problems we solved."
The shift from "what our data can do" to "what our customers can achieve" separates successful data products from expensive science projects. Products deliver value; projects deliver outputs.
The fix is simple and uncomfortable: define what success looks like before you define what to build. Measure decisions made, not dashboards shipped. If your roadmap reads like a feature list instead of a value proposition, you're building a project, not a product.
3. Teams over Tools
After building $7M in data product ARR, I can tell you the technology was never the hard part. (I spent six figures on a BI platform that solved the wrong problem before I learned this.) DuckDB vs Snowflake doesn't matter if your team can't make good decisions. Getting the right people in the right roles, with clear ownership and strategic thinking, that's the 80% that determines success.
Tools are commoditized. Judgment isn't.
Before you debate DuckDB vs. Snowflake, ask: does your PM know what customers actually need? Does your data lead have authority to say "not yet" on a release? Get the people right first. The tools will follow.
4. Judgment over Automation
Nate Jones describes three layers of AI capability: prompt engineering (what to do), context engineering (what to know), and intent engineering (what to want). Almost nobody is building the third layer. That's where the failures live.
Klarna proved this. Great prompts, great context, zero intent alignment. Nobody encoded "build lasting relationships" in a way the system could act on.
I've trained 100+ executives on GenAI adoption. Every session proves the same point: teams that obsess over the technology fail. Teams that focus on the judgment framework, who decides, when to override, what requires human review, succeed. As Winter-Tear puts it: "Tools can encode clarity. They cannot create it." The judgment principle isn't about humans being better than AI. It's about clarity being a prerequisite that no tool provides automatically.
AI handles synthesis, pattern recognition, mechanical analysis. Humans handle strategy, ethics, and anything where context matters more than speed. And if AI starts eroding trust? You pull back. Speed you can recover. Trust you can't.
5. Uncertainty over Certainty
Data work requires exploration. You can't know if the data quality supports your hypothesis until you've tested it. You can't predict algorithmic bias until you've examined the training data.
Fixed time, variable scope respects this reality. Two-week sprints pretend data work is predictable. (It isn't. If your data scientist can scope a problem in two weeks, it wasn't a hard problem.) Six-week cycles acknowledge the uncertainty.
Shape for 2 weeks before committing to 6-week cycles. Make go/no-go decisions based on what you've actually discovered, not what the Gantt chart predicted. Success means "did we solve the problem?" not "did we finish the backlog?"
6. Ownership over Handoffs
The strategy-execution chasm kills data products. When the "strategy team" hands off to the "execution team," context gets lost and ownership fragments.
The people shaping the product are the people building the product are the people learning from customer feedback. No strategy consultants. No separate "architecture team." No handoffs. If that sounds impossible in your org, that's the diagnosis, not the objection.
7. Ethics over Expediency
The 5th risk—ethical data risk—is non-negotiable. When deadlines loom, teams cut corners on bias testing, privacy reviews, and transparency mechanisms. That's how algorithmic discrimination happens. That's how trust collapses.
Data Lead ownership of ethics isn't bureaucracy. It's insurance against existential risk.
Data Leads have authority to delay releases for ethical concerns. Bias testing, privacy review, and transparency mechanisms are never negotiable scope. Governance that enables speed, not bureaucracy that prevents it. But when ethics conflicts with deadlines, ethics wins. Every time.
Seven principles. Sounds clean. Maybe too clean. I've watched plenty of frameworks that look perfect in a blog post and collapse on contact with a real team. The honest version: I've violated every one of these principles at least once. Trust over Features is easy to say when you're not staring at a renewal deadline with a feature gap. Judgment over Automation is easy to say when the CEO isn't asking why you're not shipping faster with AI.
These principles survive not because they're comfortable. They survive because the cost of ignoring them was always higher than the cost of following them. Usually I learned that after the fact.
The Eight Strategic Principles
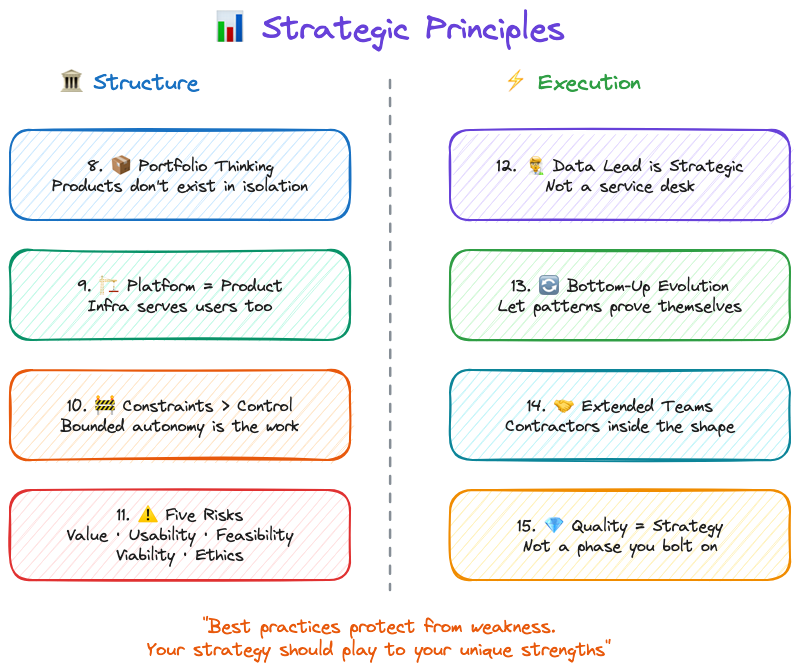
Philosophical principles are the beliefs. Strategic principles are what those beliefs look like when you're actually running a team.
One note before we get into these: the point of strategy is to be different. To find alpha. Copying best practices protects you from known weaknesses, but it doesn't play to your strengths. These strategic principles are a starting position, not a ceiling. If your team has a way of working that creates advantage nobody else can replicate, protect that. Don't sand it down because a framework told you to.
The Data Product Strategy Stack
Pichler's strategy stack goes from business strategy at the top to product backlog at the bottom. For data products, I add two layers he doesn't: portfolio strategy (because when data is both infrastructure AND product, individual strategies fragment without it) and platform strategy between portfolio and product (because your architecture IS your competitive moat, not just an implementation detail).
Everything else flows the same way. Except one thing: the flow is bidirectional. Discoveries from building, quality issues from shipping, feedback from customers, all of it flows back up to change strategy. Strategy that doesn't adapt to reality is just a slide deck.
8. Data Products Need Portfolio Thinking
When data is both infrastructure (shared platform) AND product (revenue-generating offerings), individual product strategies can create fragmentation, duplication, or competitive conflicts.
Portfolio strategy sets boundaries that enable product strategies to innovate.
I've watched this pattern across healthcare data companies at every scale. IQVIA, Truveta, Change Healthcare, Veradigm, all of them run multiple data products that share infrastructure but serve different markets. The ones that win have portfolio-level governance. The ones that don't end up with three teams building slightly different versions of the same cohort builder. At NeuroBlu, we had a healthcare data platform and provider network SaaS with unified trust frameworks but distinct product strategies. The portfolio layer is what kept them from cannibalizing each other.
Portfolio strategy sets data governance standards, trust frameworks, platform patterns, and cross-product sharing protocols. Product strategies determine target markets, value propositions, feature sets, and pricing models. Head of Data Products owns portfolio plus platform strategy. Product Squads own individual product strategies.
9. Platform Strategy Is Product Strategy
Traditional products can separate "product decisions" (features, UX) from "platform decisions" (infrastructure, architecture). Data products can't. Your data architecture IS your competitive moat. Platform decisions are business decisions.
CensusChat choosing DuckDB enabled sub-second queries on 44GB datasets, which enabled the product value proposition (instant insights from massive datasets). NeuroBlu choosing a columnar architecture enabled 30x data scale (0.5M → 32M patients), which enabled enterprise contract wins. Snowflake's architecture—separation of storage/compute, data sharing—IS their product differentiation, not just infrastructure.
Platform decisions get evaluated for business impact, not just technical merit. (If your CTO and your Head of Product haven't co-authored a roadmap, you have two roadmaps. That's worse than having none.) Technology roadmap and product roadmap are co-created, or they're fiction.
10. Alignment Through Constraints, Not Control
Top-down control kills innovation. Bottom-up chaos kills alignment. Portfolio strategy must balance both.
Dylan Anderson puts it plainly: "To succeed with Data Governance, organisations need one thing above all else: Structure. Without it, you will frustrate individuals and undermine the role governance should play." Structure doesn't mean bureaucracy. It means boundaries that enable speed.
Winter-Tear identifies what happens without those boundaries. Organizations survive on what he calls "tolerated vagueness," fuzzy ownership, undocumented escalation paths, informal workarounds that humans patch in real time. That works until you add AI or scale the team. Then, as he writes, "delegated systems don't simply accelerate the workflow. They accelerate the consequences of whatever ambiguity was already there."
Set boundaries, not mandates. Product strategies innovate within constraints.
For data products, constraints might look like: "All products must maintain 99.9% data accuracy" (trust framework), but how you achieve it is your choice. "Algorithmic bias testing required before production" (ethical data risk), but which testing methodologies you use is up to you. "Data lineage must be observable" (quality standard), but which lineage tools you choose is your call.
Portfolio strategy defines "what" must be true. Product strategies define "how" to make it true. Constraints enable autonomy by clarifying boundaries. Betting tables resolve resource conflicts across products.
11. Strategy Owns the Five Risks
Traditional product strategy addresses four risks (Marty Cagan): value, usability, feasibility, business viability. Data products add a fifth.
Product strategy must address the fifth risk with the same rigor as the other four.
Cagan's four are familiar: Value (will customers use it?), Usability (can they figure it out?), Feasibility (can we build it?), and Business Viability (does it work for our business?). Most teams address these, even if imperfectly.
The fifth risk is the one that gets skipped: Ethical Data Risk. Can we build trust while delivering value? This means bias testing, privacy review, transparency mechanisms, governance design. Owned by the Data Lead, not by committee.
Ethical data risk cannot be "addressed later" or "fixed in production." When risks conflict, speed vs. ethics for example, the Data Lead has authority to delay. Address it or don't ship.
12. Data Lead Ownership Is Strategic
Adding a Data Lead to the team seems like an operational decision. (It's not. It's the most strategic hire most data teams never make.)
Data Lead ownership of the 5th risk is strategic recognition that data products have different DNA.
Trust destruction is existential. A single data quality incident can destroy an entire product's market position. Ethical risk requires expertise—algorithmic bias, privacy, transparency aren't things product managers can "pick up." And there's no fallback position. If the Data Lead doesn't own ethical data risk, nobody does. It won't be owned by committee.
Roman Pichler talks about empowered teams having authority to create and evolve product strategy over time, offering three key benefits: fast decision-making and strategy-execution alignment, increased productivity, and value focus.
For data products, empowerment requires four pillars, not three: Product Manager (market & strategy), Tech Lead (architecture & implementation), Design Lead (UX & visualization), and Data Lead (data science, engineering, ethics).
Data Lead is present from strategy formation through delivery. Data Lead has veto authority on ethical concerns. Data Lead is accountable for trust metrics. If you don't have someone in this seat, ask yourself who's accountable for the next data quality incident. If the answer is "everyone," the real answer is no one.
13. Bottom-Up Strategy Evolution
Strategy that ignores reality fails. Top-down strategy that never adapts to discoveries is dogma.
Quality issues from building reveal portfolio gaps. Customer feedback reveals strategy pivots. Platform problems reveal architecture changes. The flow in the strategy stack goes both ways. Strategy is a living document, not sacred text.
14. Extended Teams for Extended Reach
Your core squad (PM, Tech Lead, Design Lead, Data Lead) doesn't have every expertise you need, so bring in legal, clinical, commercial, and compliance as collaborators early in shaping, not as gatekeepers late in approval.
At NeuroBlu, Legal identified HIPAA considerations upfront, not during QA. Medical Affairs validated the clinical value proposition before launch, not after. The difference between "we invited compliance to review" and "compliance helped us shape it" is about six weeks of rework.
15. Quality Is Strategy, Not Tactics
Dylan Anderson reframes quality in a way that changed how I think about it: "Data quality is an output, not an input. It is a symptom of numerous underlying root cause issues within the data ecosystem." Most teams treat quality as something to test for. Anderson argues that's backwards. "Tackling just 'data quality' will lead to potential short-term gain but continued long-term pain."
The numbers back this up. Gartner estimates poor data quality costs organizations an average of $12.9M per year. MIT Sloan puts it at 15-25% of revenue. That's not a QA problem. That's a strategic failure.
The root causes are systemic: broken business processes generating bad data at the source, multiple conflicting data sources with no reconciliation, no established basis for quality improvement, and chronic underinvestment in governance. You can test for quality all day. If the processes creating the data are broken, testing just documents the damage.
Quality as strategy means addressing root causes, not symptoms. Quality metrics are defined during strategy formation, not QA phase. Trust metrics sit alongside performance metrics in product dashboards. Data lineage is designed into architecture from day one. Continuous monitoring replaces checkpoint testing. Quality incidents trigger strategy reviews, not just bug fixes.
At NeuroBlu, "zero major data quality incidents" was a strategic goal, not a QA goal. Led to architecture decisions, redundant validation, observable pipelines, that differentiated us. CensusChat defined quality as "results match official Census reports exactly," which shaped architecture choice (DuckDB with validation layer) over faster options with potential discrepancies.
How the Principles Collide
Principles sound clean in isolation. In practice, they collide.
At NeuroBlu, a client wanted faster cohort generation. The fastest path skipped lineage validation. Trust over Features said no. The Data Lead flagged potential bias in the underlying patient selection. Ethics over Expediency said slow down. Meanwhile, the client was asking why this was taking so long. Outcomes over Outputs said: the outcome isn't speed, it's accuracy.
We took the slower path. Added the validation. Tested for bias. Shipped two weeks late. The client didn't mention the delay once. They mentioned three times that the numbers matched their internal validation. That's how these principles work: not as a checklist, but as a decision framework when the pressure is on and the easy path is wrong.
From Kernel to Execution: Role Operating Systems
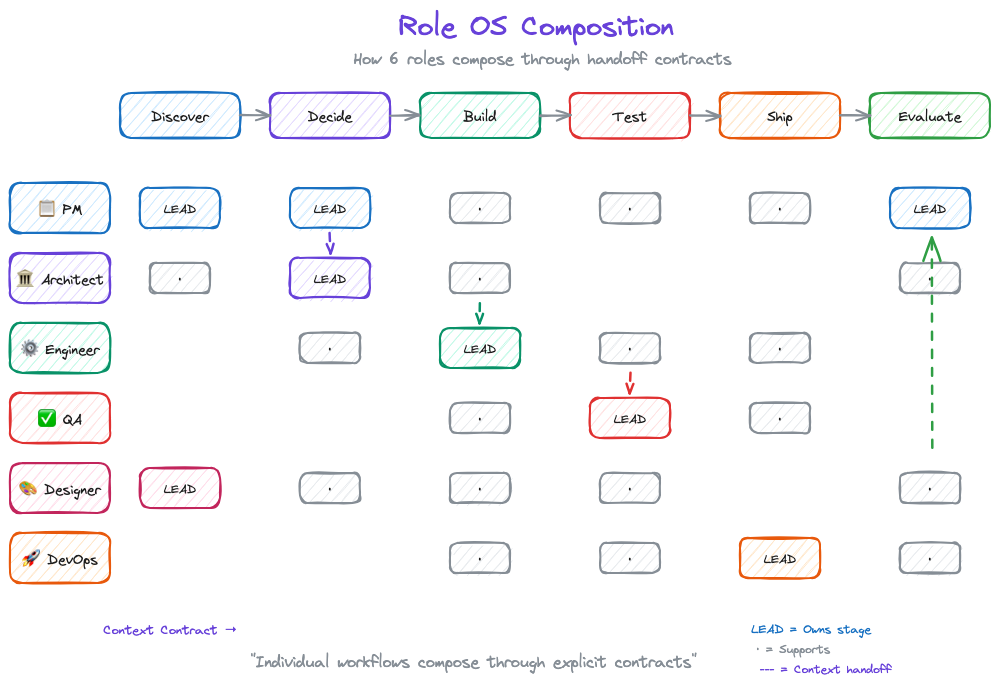
Principles are useless without execution. But here's what traditional frameworks get wrong: they jump from principles to team process. That's too big a gap.
Between "Trust over Features" (principle) and "Hold weekly quality reviews" (process) sits something critical: how individuals actually work.
DPOS v2 introduces Role Operating Systems, the layer between kernel principles and team execution.
What Is a Role OS?
Each role on a data product team operates with their own system: agents that assist them, context they consume and produce, workflows they follow. This is their Role OS.
Winter-Tear offers a sharp test for whether you've actually built one: "If you can name the workflow owner, the source of truth, the service level, and the audit trail, you are building an agent specialist. If you cannot, you are probably building a copilot, so set expectations accordingly." Role OSes are how you answer those four questions for every role on your team.
The kernel principles translate directly to Role OS design:
| Kernel Principle | Role OS Implementation |
|---|---|
| Teams over Tools | Shared context — Your OS feeds the team, not just you. The context you produce becomes input for other roles. |
| Judgment over Automation | Agents with oversight — AI assists at scale, humans decide at boundaries. Your agents handle mechanical work; you handle judgment calls. |
| Trust over Features | Deterministic where necessary — Handoffs need predictable outputs. Your Role OS guarantees quality at interfaces. |
| Ownership over Handoffs | Clear organization — Your OS owns specific lifecycle stages. You know what you're responsible for at each phase. |
The Six Role Operating Systems
DPOS v2 defines six roles, each with their own OS:
- Data PM OS — Strategy, prioritization, stakeholder synthesis
- Data Engineer OS — Pipelines, transformations, data quality
- Data Architect OS — System design, integration patterns
- QA/Data Quality OS — Testing, validation, quality gates
- Designer/BA/Visualization OS — UX, requirements, dashboards
- DevOps/App Engineer OS — Deployment, infrastructure, monitoring
Your team might have different names. You might combine roles. That's fine—what matters is that each role has a defined OS that composes into team execution.
How Role OSes Compose
Individual productivity isn't the point. Composition is.
Traditional methodologies assume everyone follows the same process. That's inflexible. Role OSes assume everyone follows their own process, connected through explicit handoff contracts.
PM OS (Discover) → Context Contract → Architect OS (Decide)
Architect OS (Decide) → Context Contract → Engineer OS (Build)
Engineer OS (Build) → Context Contract → QA OS (Test)
The team OS doesn't prescribe how each role works. It defines:
- The lifecycle stages (Discover → Decide → Build → Test → Ship → Evaluate)
- Which roles engage at each stage
- What context contracts connect them
This is what LLMs changed. Before, "my notes" stayed in my head (or my Notion). Now, structured context from your Role OS actually feeds team execution. Individual workflows compose—for real, not just in theory.
Part 3 goes deep on Role Operating Systems—what they contain, how to build them, and a complete example for the Data PM role.
If You Read Nothing Else
For executives: Your data team isn't failing—your methodology is. Stop measuring story points. Start measuring customer outcomes. The $300K we lost on one data quality incident taught me: trust is your moat, not features.
For data team leaders: The reason nobody sees your work is that Scrum ceremonies don't surface data value. These principles give you a language to explain what you do—and why it takes time to do it right.
For practitioners: It's not your fault that sprint planning feels like theater. Data work doesn't fit two-week chunks. These principles explain why, and Part 3 shows a different path.
Next up: Part 3 goes deep on Role Operating Systems. How each team member builds their own OS, and how those OSes compose into team execution through explicit handoff contracts.
Series Navigation:
- Part 1: Introduction
- Part 2: The Kernel (Principles) ← You are here
- Part 3: Role Operating Systems
- Part 4: The Integration Layer
- Part 5: Implementation