DPOS: The Operating System for Data Products in the AI Era
Your day looks like this: standup, sync, planning, review, requirements. Somewhere in there you're supposed to actually analyze data. The system was designed for software teams, not data teams. DPOS fixes that.
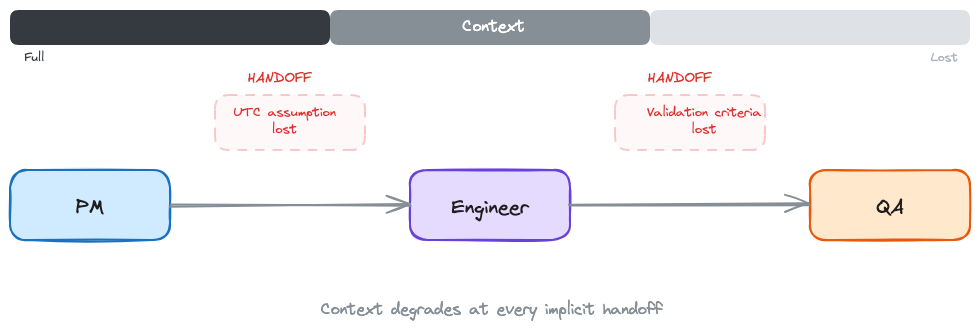
I once watched a three-month project fail because one team assumed UTC and another assumed local time. Nobody wrote it down.
That's not a code bug. That's a handoff failure. The PM's requirements became the engineer's spec, and somewhere in the gap, a critical assumption about date formatting vanished. Three months of work. One implicit handoff. Dead.
Data teams don't fail because they're slow. They fail because the space between roles is where context disappears.
The Pattern I Keep Seeing
I've built $9M+ in data product ARR across healthcare analytics, real-world evidence platforms, and clinical decision tools. Nine years. (Feels like twenty.) Multiple companies. Different team sizes, different tech stacks, different org charts.
The failure pattern is always the same: the handoffs.
At Revive, six months into leading the data product team, my data scientist looked at me mid-sprint and said: "We constantly plan but never finish. We keep pushing the interesting modeling work to the next sprint." Our designer added: "The UI keeps changing because we don't have time to explore visualization options properly." Our tech lead just nodded. He was too frustrated to talk.
Two-week sprints were fragmenting work that needed deep exploration. But the real problem wasn't the sprint length. It was that every time work crossed from one person to another, context leaked. Ask me how many retros it took to figure that out.
In a different role, I shipped a cohort analysis with a join bug that inflated numbers by 40%. Our client's analyst found it before we did. In a board meeting. They'd built their quarterly forecast on our numbers. Wrong cohort, wrong forecast, wrong resource allocation downstream. That's what happens when the handoff between building and testing doesn't include explicit quality contracts. Nobody's job to catch it, so nobody caught it.
It's Not Velocity. It's the Gaps.
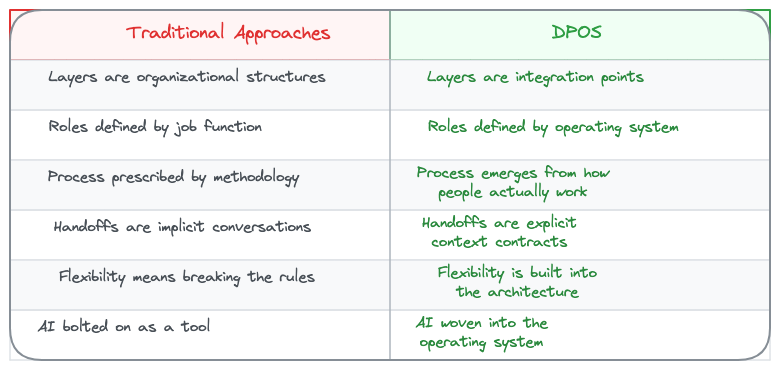
Every methodology I've tried shares the same blind spot: they treat handoffs as informal conversations.
Scrum optimizes for delivery cadence. I've run Scrum with data teams at three different companies. Here's the pattern: the data scientist needs four weeks of exploration before they can even scope the problem. You force that into a two-week sprint and they either rush the exploration (bad) or carry it across sprints (which defeats the point of sprints). Meanwhile the engineer is waiting for a spec that doesn't exist yet because the scientist hasn't finished exploring. Context leaks at every handoff because nobody has time to document what they learned before the next ceremony starts.
Kanban optimizes for flow. But data products need quality gates, ethical review, and validation that don't fit a pull-based model. You can't just "pull" the next data quality check when you're ready for it. Sometimes the data quality check needs to block everything.
CRISP-DM assumes linear progression: business understanding, data understanding, preparation, modeling, evaluation, deployment. In practice, you discover requirements while building. You find data quality issues in production. You loop back constantly.
SAFe tries to solve coordination at scale. But the coordination overhead suffocates the exploratory work that makes data products valuable.
Each of these gets something right. Scrum's retrospective discipline. Kanban's work-in-progress limits. CRISP-DM's insistence on business understanding before modeling. Good ideas, all of them.
But they all assume handoffs happen through conversations. Tickets get passed. People sync up in meetings. Context travels through Slack messages that disappear in a week.
For software products, that works well enough. The code is the artifact. It either compiles or it doesn't.
For data products, the context IS the artifact. Why this cohort was defined this way. What assumptions went into the model. Which edge cases were intentionally excluded. Lose that context in a handoff, and you get a UTC bug that kills three months of work.
What If Handoffs Were Contracts?
That question changed how I run data teams.
What if every time work crossed from one person to another, there was an explicit agreement about what context transfers? Not a meeting. Not a ticket description. A contract: here's what I produced, here's what it assumes, here's what you need to know before you build on it.
For the engineer, this means not reverse-engineering stakeholder intent from a Jira ticket. The contract tells you what the PM's discovery actually found, what it assumes, and what edge cases were already considered. You build from what's written down, not from guessing what the PM meant.
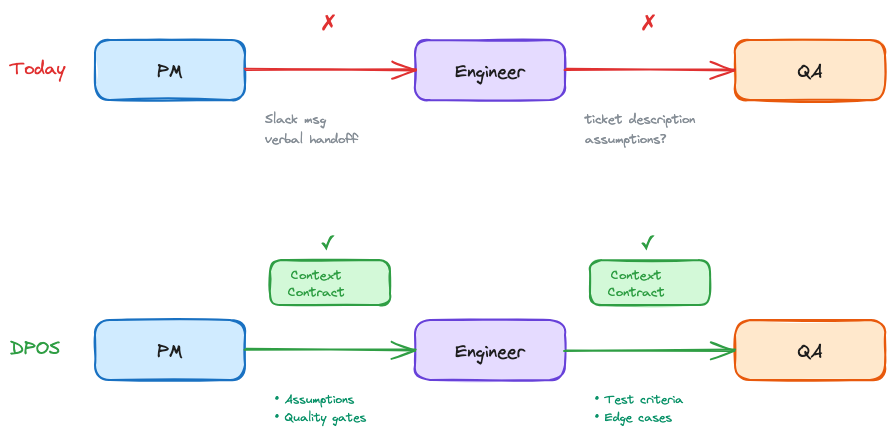
I've been building a system around this idea for the past two years. I call it DPOS, the Data Product Operating System.
DPOS works at two levels:
Individual. Each role on the team has their own operating system. The PM's workflow for synthesizing stakeholder feedback is different from the engineer's workflow for building pipelines. That's fine. Each person works the way they actually work, not the way a methodology prescribes.
Team. DPOS connects those individual systems through shared context at lifecycle boundaries: Discover, Decide, Build, Test, Ship, Evaluate. A set of principles that don't change (the kernel), and explicit handoff contracts that connect individual workflows into coordinated execution. The stages aren't the interesting part. The handoffs between them are.
Why Now?
DPOS is about explicit handoff contracts. You could implement these with shared docs, templates, or well-structured meeting notes. Before AI, I did exactly that. It worked, but the documentation overhead was brutal.
What's changed is that AI makes this cheap. At Holmusk, I ran 315 customer queries + questions through an AI analysis pipeline (Gemini) and got structured themes, segment breakdowns, and a prioritized issue list in 20 minutes. Before that, the same synthesis took me two hours of manual categorization. That synthesis becomes the handoff artifact my engineer actually reads, because it's specific enough to build from.
The documentation now happens as a byproduct of the work itself. AI makes DPOS faster. But the principles come first. The tooling is up to you.
What Makes This Different
I've tried forcing teams into Scrum. I've watched CRISP-DM die slow deaths in organizations that adopted it on paper and ignored it in practice. I've seen teams "customize" Kanban until it was just a wall of sticky notes with no structure.
Stop making people fit the framework. Let the framework emerge from how people actually work.
What's Coming
This is Part 1 of 5.
- Part 2: The Kernel. Principles that never change. Trust over Features. Judgment over Automation. The philosophical and strategic foundation.
- Part 3: Role Operating Systems. How to build an OS for each team role. Deep dive on the Data PM OS as proof of concept.
- Part 4: The Integration Layer. How individual operating systems connect into team execution. Where this table gets the nuance it deserves.
- Part 5: Implementation. Getting started patterns for greenfield, brownfield, and AI integration paths.
After the core series: practical Role OS guides for each core data product role, with templates and real workflows.
So What?
Explicit handoff contracts sound obvious. So why doesn't every team do this?
Because the hard part isn't the contract format. It's the principles underneath. When a data scientist's exploration contradicts the PM's roadmap commitment, whose context wins? When a quality check reveals a problem two days before launch, does trust outweigh the timeline? (Spoiler: it does. I learned that one the expensive way.)
Part 2 is about the kernel: the principles that make those calls before the pressure hits.
Next in series: Coming soon: Part 2 — The Kernel (Principles)
Series Navigation:
- Part 0: The Problem
- Part 1: Introduction — You are here
- Coming soon: Part 2 — The Kernel (Principles)
- Coming soon: Part 3 — Role Operating Systems
- Coming soon: Part 4 — The Integration Layer
- Coming soon: Part 5 — Implementation